There’s a lot of science and a lot of “Woo Hoo, it works” and a heap of pragmatism in how I arrived at this point. Scroll to the bottom for the TL;DR
After lots of wasted time tweaking the % values for the mills issue, once I stopped doing things that could take processing time away from LMIC during send, it wasn’t an issue.
This is coupled with os_runloop_once(). It’s not totally clear in my code, but once I want to send, the sleepOK=false effectively prevents any of my code running so LMIC can do its work. Unless we reach the next send interval when it all gets overrun by a new cycle (but copes, I tested).
I found a whole pile of commentary about the LMIC needing its internal timer to be updated after wake from sleep and various suggestions on how to do so, most of which do not appear to have worked for people as they were trying to patch the OS modules timer values with complex calculations which seemed to mostly upset it.
Rather than using a library for sleep, I followed Nick Gammon’s detailed info on setting the sleep mode exactly as I want along with his very useful tips on turning off IO and the ADC.
Having printed out and read the source code for MCCI LMIC, my personal take is that the use of the OS module to provide timing for the receive windows ended up with it spreading across the whole system and from code review, it’s very much embedded in the design. So much so that I’ve seen ESP libraries that incorporate a RTOS for the whole system whilst the LMIC has it’s own mini-scheduler inside!
Part of this development journey saw the very first hand-soldered TinyThing last May using the osjob_t sendjob with its call to do_send() and whilst I tried to use a similar mechanism for sensor checks and a feedback LED, it was getting messy. I don’t mind callbacks, I don’t mind a task scheduler (having written one in assembler for PIC), but I do like my code to follow a journey and as I wanted something that was going to be quick & simple to implement a new sensor, considering some need a warm up time (like the DHT11 & BME680), scheduling jobs for sensor turn on, warm up, read, turn off and so forth was filling memory & code spaghetti & wasn’t inspiring confidence.
Whilst I was doing the above, I was also trying other versions of MCCI, forks & implementations and when I looked in to the feasibility of tracing the LMIC internal code to check on memory & what it was actually up to, I lost DAYS of time and my sense of humour.
So, by a process of simplification by elimination over last summer, I entirely removed the user facing jobs so I wasn’t relying on the mini-OS to run anything I wanted to control but decided that giving the LMIC a chance to do anything I’d not spotted between sleeps was probably for the best. I appreciate this isn’t totally scientific, but as I’ve been running a software & electronics business for 26+ years and cutting code for over 40 years now, I know the power of pragmatism.
So having hacked on this May - Sept I needed to ship something, I had a test Thing running for some time by now on my desk so I could see I’d reached some level of stability. I moved on to low power mods and ended up with a test Thing running on solar blocking the view out my office window. I created the PCB, made the first desk Thing and then built what we call the AA Power Test and put it in a plant pot on the decking outside.
From my time spent watching the Arduino Serial Monitor whilst spamming both my gateway & TTN with repeated small uplinks, I suspect memory management can’t keep up in the face of using various libraries - many of which upon investigation suffer badly from bloat. I think the MCCI LMIC library has suffered too but until I’ve written my own LoRaWAN stack, I’ll keep my detailed opinions to myself. All I’d say is, no jobs, use a timer interrupt!
There have been some cleanups & tweaks and a fair number of deployments but as soon as I added the BME680 library for a project, I knew I wasn’t heading in the right direction so started thinking about where to go. I do use an Arduino Nano Every for projects that need to be Arduino + LoRa chip. But now I have a TinyThing Mk2 with a RAK4200 in place of the RFM95W, I get most of my flash & RAM back. It’s a toss up between using a RAK4260 or going ATmega4809 + LoRa chip, I’ll probably do both.
Having woken up this part of my coding brain I will look again at some of the details but I’m not inclined to burn up time like I did previously on this. It may be that we can eliminate the os_runloop_once() during sleep, that’s simple enough to try and I can see what impact this has on the battery. I have more hardware now that I can use to measure & log current consumption far more accurately so I may take some readings to bring some science to the power consumption for this combination. From my experience using batteries on balloons, I sort of just know that the AA Power Test is doing very well considering the LED and serial port.
TL;DR: No milli tweaking appears to be needed if you aren’t running anything else during a send and research & experimentation found os_runloop_once() every 8 seconds worked and I wasted too much time to investigate further.
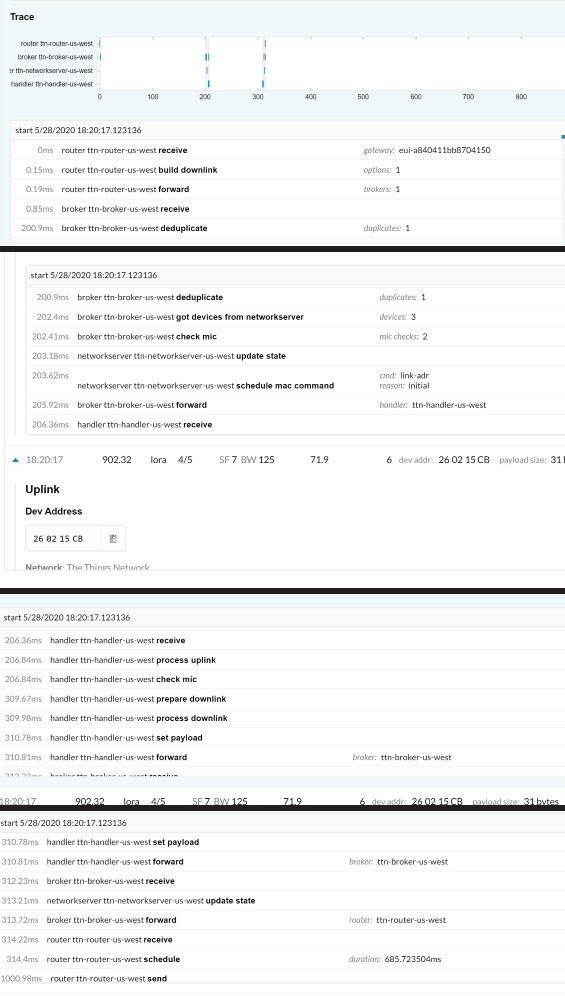
 , I will put more work in making my posts. I just got really excited cause I haven’t seen a downlink (yes it’s a downlink trace) in a long time. The uplink associated with this downlink was received by the TTN, so one device broke through a 5 day period of silence.
, I will put more work in making my posts. I just got really excited cause I haven’t seen a downlink (yes it’s a downlink trace) in a long time. The uplink associated with this downlink was received by the TTN, so one device broke through a 5 day period of silence.