Use the below to test, what cluster are you working to?
You can configure your gateway to any one of the 3, it is frequency independent of you end devices (So to the au1 you can have a gateway that is EU frequency band)
Use the below to test, what cluster are you working to?
You can configure your gateway to any one of the 3, it is frequency independent of you end devices (So to the au1 you can have a gateway that is EU frequency band)
There are no such things as attempted uplinks. Either an uplink arrives at the gateway or it doesn’t. If it does and the CRC is correct it will be forwarded to the back-end. As the status messages arrive, the uplinks should arrive as well.
The RSSI shouldn’t be a problem. The sensors are placed close by.
Thanks, we will try this out then!
I assume they are, yes. It is possible for us to ssh into the gateway and configure it as needed.
Yes.
We are using the eu1 cluster, and the gateway + end nodes are placed in Europe.
Sorry for the confusion. We see some some sporadic CRC errors in the log, but some seem OK. This is what the console looks like for the gateway and for one of the devices:
To high RSSI is a big problem.
Check the latency to nam1 and au1, might be less than eu1
The RSSI is around -76.
How would you do this best? Simply doing ping eu1.cloud.thethings.industries from within the gateway only yields timeouts.
The 3 link I supplied up top ping the AWS network, the stack is deployed on AWS.
I can’t access a website from the gateway. I can only ssh into the gateway from remote. Can this be done from the command line?
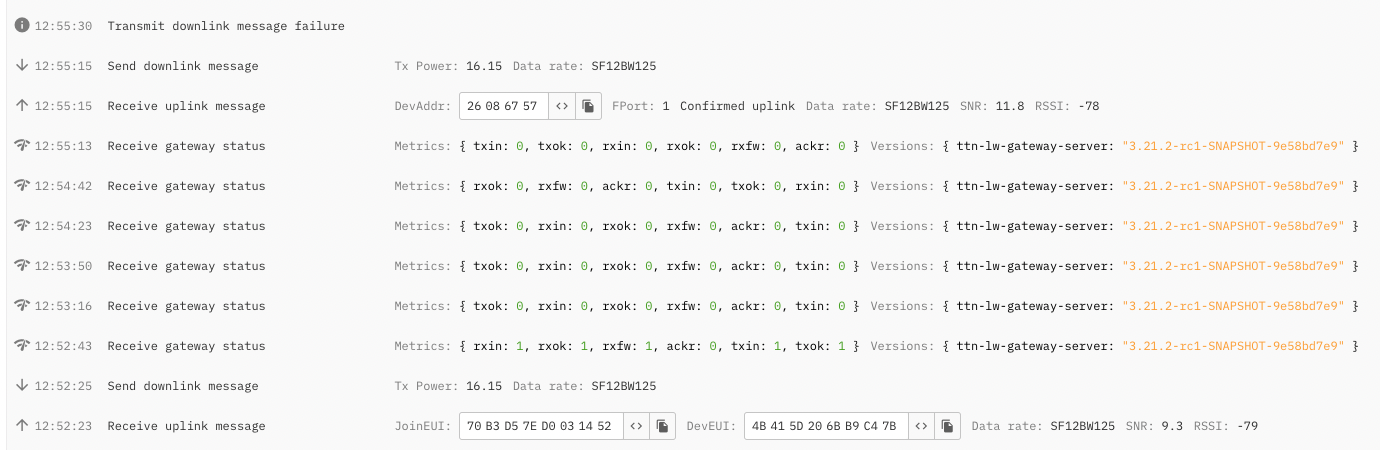
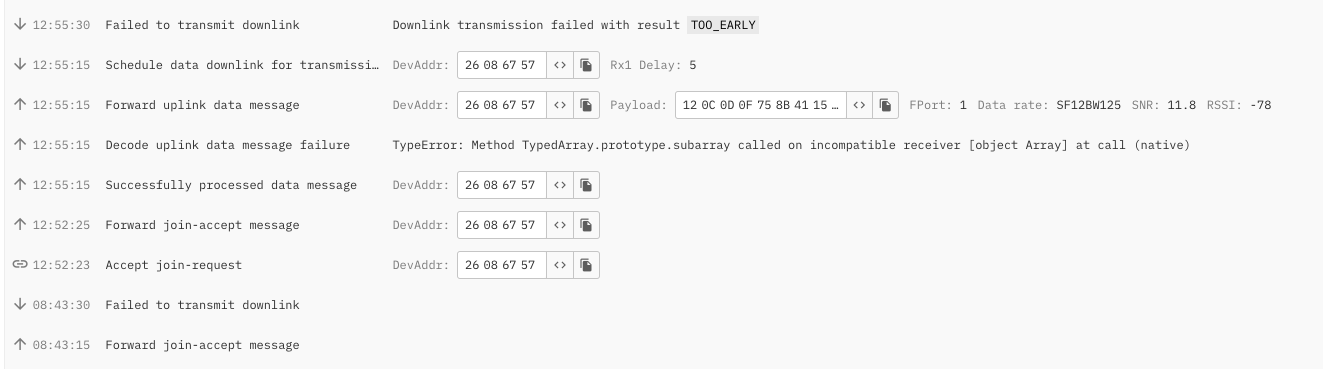
Notice from your picture that you are using confirmed uplinks - these are really to be avoided if possible - even on a private instance ![]() Despite the reasonable RSSI for the one that gets through I note use of SF12 - again to be avoided/moved from under ADR if possible…also join at bottom at SF12? What are nodes? What firmware/how configured? For the recieved uplink FCount =? How all nodes configured =OTAA or ABP - from the Join assume that one is OTAA… is the one with Dev ADDR 26086757 one of yours or a ‘foreign’ device? (Are you seeing that device in your Application/Device Console?)
Despite the reasonable RSSI for the one that gets through I note use of SF12 - again to be avoided/moved from under ADR if possible…also join at bottom at SF12? What are nodes? What firmware/how configured? For the recieved uplink FCount =? How all nodes configured =OTAA or ABP - from the Join assume that one is OTAA… is the one with Dev ADDR 26086757 one of yours or a ‘foreign’ device? (Are you seeing that device in your Application/Device Console?)
Actually jus notice its 2 pics… ![]()
Clearly a decoder problem also?
Stick the SIM card to a cellular router and test with a PC
Wasn’t aware of this. Thanks for pointing out! ![]()
The nodes are our own with custom firmware, where we’ve implemented ADR so the SF is increased as long as the node fails sending uplinks, hence it should decrease to SF7 when uplinks flow successfully again ![]()
All are configured for OTAA.
They are all ours. They are listed in Application.
That’s correct. We have problems with the JS decoder in TTN, so we are manually decoding the packets in our Cloud Solution ![]()
Thank you for the suggestion, however it’s not possible for us at the moment since we are remote debugging this.
If they are 5-50m away with reasonable (say <50 → <115) RSSI then you should see joins OK at SF7/8/9… SF12 suggests you have configuration/behavioural problems with these nodes!
Where in the world is the gateway?
And unfortunately you can’t fix all problems remotely. ![]()
Switching to Basics Station mode seems to have fixed the problem. Thank you all very much for your help! ![]()
Pretty much everything after this wisdom looks like advanced guessing or suggestions that need time to be answered before more suggestions are made - I’d highly recommend slowing down responses because if a change is made that loses remote access to the gateway, someone has to go on a fly-drive holiday.
As per protocol, we know the OP has mastered the art of the drip feed information - @LasseRegin, please be more expansive with answers - ten minutes giving us everything will probably save the volunteers subbing for your €200 saving on a support contract a whole heap of time. Also, most of everything typed in response is essential detail - ping utilities were provided, you dove straight to the command line. I’m not sure why Johan wants you to move an EU installation to half way round the planet either ![]()
Here’s what we seem to know:
The refinement of the devices can come after resolving why the basics of uplinks not being relayed is solved.
Being a community, we share solutions here - what detailed differences did you see on the gateway log, the gateway console and the app/device console that lead you to believe this is resolved?
Has it also solved the SF12 join problem or is that still showing (and needs fixing) - if so likely your device firmware needs refinement.
@descartes at -78/79 RSSI atleast one device is in the sweatspot for placement/signal strength … allowing for coding gain likely equivalent to say -85-95 at lower SF’s… though even with ‘thin wood walls’ inbetween would be concered at 5m seperation if ant’s planar aligned! ![]()
The latency for me to
Ireland eu-west-1 635 ms
Sydney ap-southeast-2 560 ms
N. California us-west-1 647 ms
I have a EU installation.
Please suggest the cluster I should use?
It all depends where you are siting in the world, some times latency is not that related to distance.
The OP said it was an installation in the EU …