Last night I have captured all LoRaWAN traffic that the community gateways of TTN-Apeldoorn and my own (a total of 14 gateways) received over a period of 18 hours. The result is presented in the following table:
KPN is a Dutch commercial LoRaWAN operator
The analysis is done on all non JOIN request uplink messages and analysed the device address. This is not 100% exact but because of the number of packets, I expect that the results are representative:
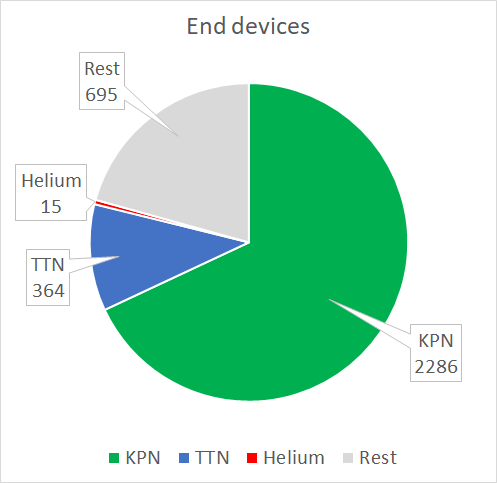
KPN has 2286 active end devices that send 20425 packets. TTN has 364 active end devices that send 79451 packets. Helium has 16 active end devices that sent 441 packets.
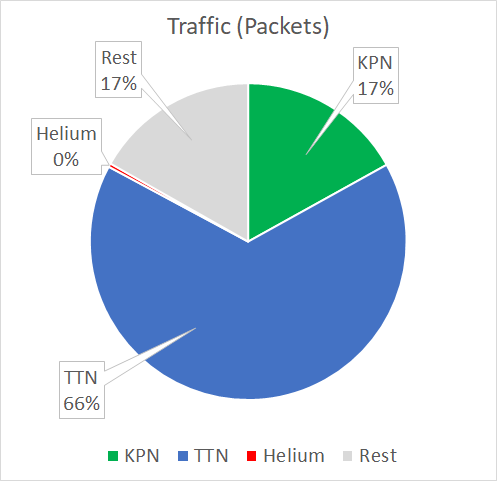
From all received packets 66% are related to TTN while 17% of all packets are from KPN end devices. The rest of the packets (17%) are not related to these networks.
How about the 0100da30 end device
This device address is heard over all 14 gateways. From these gateways, 50% have no geographical binding as they are too far away for line-of-sight and they do not share the same coverage area. Therefore it is not possible that transmissions by “0100da30” are done by a single and unique end device unless it is airborne.
My conclusions so far
- Although KPN has more end devices (packet rate per hour is 1135), TTN is occupying the frequency spectrum the most with 66% of all received packets and a packet rate of 4414 per hour.
- With 14 end devices and a packet rate of 25 per hour, Helium has no serious presence in the 868 MHz band.
- If the “0100da30” end device can be related to Helium, the packet rate of Helium end devices increases to 126 packets per hour.
When evaluating frequency occupancy, the “0100da30” end device is not misbehaving. From LoRaWAN specification point of view there may be other reasons to judge otherwise.