I’m working on a project whose objective is to get various data from animals using sensors. The project has 3 parts:
The first part is to create the sensors.
The second part is to create and install the gateways to receive messages.
The third part is to create an application to get the data.
The thing is, that I’m only working on the application that will get the data. I made a server using NodeJS to receive the data, store it in a database and send emails when there are problems.
Now, a few days ago, I was told that I would also need to detect when the gateway is down and I have no idea how to do that. Any advice?
Edit: It is expected from the application to have a way to monitor the gateway without using a node. That’s why I’m having problems and have no idea what to do.
one way to do it is to put a ‘heartbeat’ node that transmits a very small payload on a dedicated port.
if the application don’t receive that payload something could be wrong, be it the network / gateway (or the ‘heartbeat’ node itself
Thanks for the answer, unfortunately, that idea was rejected. Originally, I was planning on watching when was the last message received from a gateway and, if an specific amount of time has passed without receiving messages (the animals are supposed to be in area covered by various gateways), it would send an email that there is a problem with the gateway.
It is expected from the application to have a way to monitor the gateway without using a node. That’s why I’m having problems and have no idea what to do.
Sorry for not being more specific in the first post
Part of a ‘gateway being up or down’ is whether it can receive and process LoRa radio packets from nodes…mechanisms may show if e.g. GW functioning as a cpu/computer system, they may show if network connection working and you could potentialy check if the packet forwarder is running and potentially restart the service if not (which GW/packet forwarder are you using/planning on deploying?) but at @Borroz suggests all that is moot if the RF front-end is down - e.g. as a result of static damage during install causing a latent failure or e.g. as a result of a close proximity lightning strike that has knocked out the RF front end…the only way to check that is to have a node running as a heartbeat and checking that the signal is received ok then processed all the way down the signal chain to the Network Server…so as a minimum 1st step I’m with Rob and would use a node…if you see no heart beat you can then start investigating other issues (perhaps automatically/under script control)…checking forwarder, checking GW core processor/os operation, checking the backhaul network connection etc. FWIW I have what I consider heartbeat monitor nodes - sometimes doubling up as functional nodes testing e.g. temp/humidity etc. running in range of >60% of my GW’s with plan to get that to 100% over the summer. If a problem is flagged it is usually because the node has run out of battery power or if on a supply that supply has failed…and fixing that often a lot easier than getting to an inaccessible GW! All future deployments will have atleast one HB Node deployed in support within 200m-2km for a real world check.
Unless it’s expected that all nodes (all animals) could get of reach of a specific gateway for a long time, I’d say you’ve got your heartbeats there and there’s no need for specific heartbeat nodes.
It’s unlikely that all nodes break down at the same time, so if all gateways are expected to receive at least a few animals’ uplinks at least once every, say, 2 hours, then your application could simply keep track of the last message for each gateway. (Using the array of gateways in each uplink’s meta property.) And if you have access to the gateway’s data then even uplinks from other users, if any, can be the heartbeat.
(Apart from checking if each gateway is seen every now and then, I’d do the same for every node. If not seen, then the animal has run off or its node is broken. But I guess you already thought about that.)
True for higher trafficked gateways, I have a few where traffic is ‘bursty’ for perhaps a few days per week or per month - typically when specific people, vehicles, plant & equipment or animals are in the area - so good to know operational before needed Which is why currently only some have HB nodes.
Have seen situations where moving livestock (horses & cattle) and supporting plant/equipment, even a few hundred meters in gently rolling countryside, typically in country road ‘canyons’ lost signal from one gateway to another even with GW’s in reasonably close proximity as if GW’s not very high it doesnt take much terrain masking to loose signal. A farmer moving cattle from pastures on one side of a hill to another to optimise grazing can mean a GW looses all its usual traffic whilst the alternate field in use…
It was expected to depend on the gateways. The idea of detecting if the gateway was working or not depending of the messages received was rejected because it was considered archaic. Or it could also be possible that there was a faillure of communication where either my explanation was not good enough or the idea was not fully understood. Or both.
In any case, getting more ideas of how to do that is good, because I would get alternatives to get a solution. For example, I had not contemplated @Sysco idea. Even if it wasn’t exactly what I was looking for, I had to think about how it could be possibly used to achieve the objectives. @arjanvanb’s solution was the one I contemplated to keep track of the time when a device was last seen and I planned to also use it for the gateways (and it’s working pretty well for the device that it’s is being used for tests).
We experienced an outage of our NOC. This resulted in gateways being indicated as offline while being online and forwarding traffic as usual. This also resulted in gateway traffic not being shown in the console.
Need to be aware of historic device or packet-forwarder specific outages in the back end. e.g. see recent reports of the TTIG’s going offline (due to the stability of the ‘patch’ that brings TTIG packets into the legacy V2 back end?) even as other GW’s were happily routing data through and hence visibly functional in the NOC, whilst packet-forwarder issues seem to be less common these days you need to be cognicent of the possibility…also whatever solution is put in place I dont think many people yet know how such monitoring systems will perform once TTN migrates V2 to V3 stack? and that cant be too many months away now?
@jlhc any thoughts on my earlier q as to whch GW/packet-forwarder you are using/considering as that may help forumites guide you better in finding a solution?
Speaking from experience (monitoring 10 gateways using this method for a couple of years) I know NOC outages are easy to recognize. If a single gateway is reported to have issues that is a gateway issue. If multiple gateways report issues it is probably a back-end technology issue (Semtech UDP, TTN connector or BasicStation). If all report issues it’s the NOC or my internet connection .
Looking at how often these occur:
Single gateway most often. Multiple times a month for short periods. Probably maintenance to the internet connection at that location.
Multiple gateways happened a couple of times of the past two years for Semtech UDP and TTN connector. BasicStation is the worst at the moment due to the work-around used to ‘integrate’ it into the V2 stack.
All gateways happens every couple of months on average when looking at the last year.
No idea, I have yet to see any of the gateways. The people who are working with them are in another city. The only thing of the hardware I’ve seen is one of the sensor’s prototypes. The only thing I had to work with was the data from the sensors.
I’ll try to get in contact with the coordinator, but until the Monday, at the earliest I won’t be able to answer.
In case you missed it (and assuming you’re using TTN): that data also includes details about the gateway(s) that received the uplinks.
(But of course your application will only get those details for uplinks of your own nodes/sensors that are registered to that application, not for any other node’s uplink that might be handled by the very same gateways.)
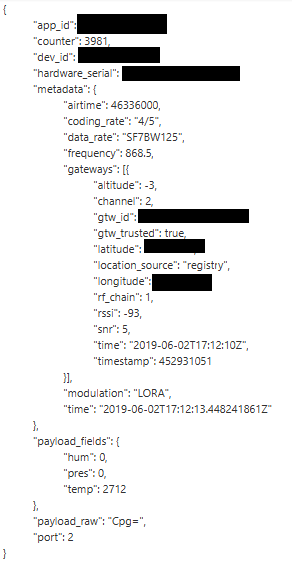
This is one of the messages that the gateway that is being used for tests is sending.
The sensor that is sending the messages is the one that is being used for tests to see what problems can happen while the messages are sent.
There are more that are being developed, but those two are the ones that are always sending data, so, they are the ones I’m watching for problems.


 All future deployments will have atleast one HB Node deployed in support within 200m-2km for a real world check.
All future deployments will have atleast one HB Node deployed in support within 200m-2km for a real world check. Which is why currently only some have HB nodes.
Which is why currently only some have HB nodes.
 .
.