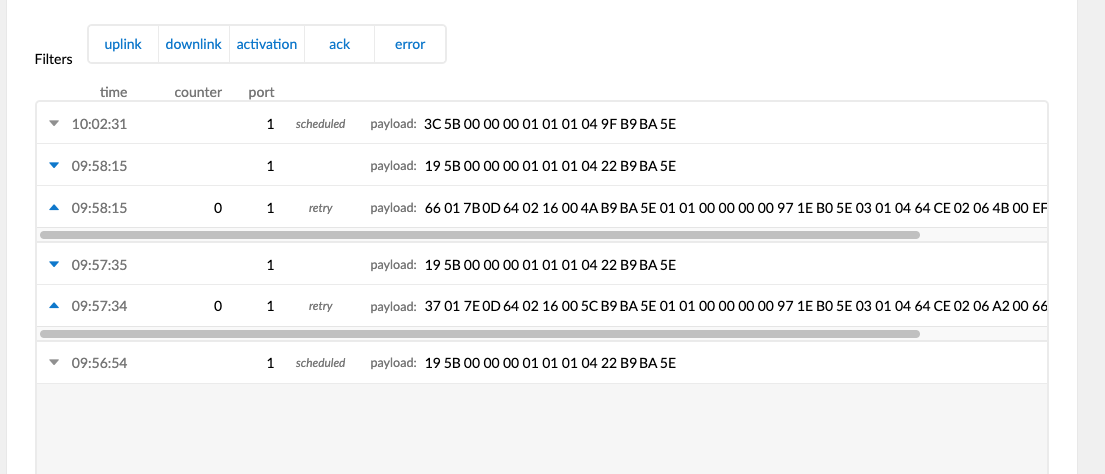
So it’s an unconfirmed downlink being sent to a device using ABP with disabled frame counters. What’s happening is that after I schedule the downlink, the downlink is being sent for every uplink. Am I doing something wrong? I attached a screenshot of my traffic from the device. I’m also seeing a “retry” for my uplinks, but that’s a different question.
I also wanted to add that I am seeing the Downlink Counter being incremented from TTN for each of these downlinks, so I’m not really sure what’s going on.
Actually, maybe it’s not. It seems to me that TTN is repeating the downlink, because it sees the uplink frame counter being repeated (which also causes seeing the “retry” label).
With proper frame counter security TTN will reject counters that are lower than the last known counter, but it seems it recognizes counters that have the same value as the last known value as being a retry. One would need to peek into the code to be sure, but I’d guess that’s what you’re seeing, despite the different payload.
Fix your device to use a proper value for its uplink counter. (And then re-enable the security setting for the frame counters.)
Actually, maybe it’s not. It seems to me that TTN is repeating the downlink, because it sees the uplink frame counter being repeated (which also causes seeing the “retry” label).
Thanks for the quick reply and the code links! That’s interesting, it seems to me that these are issues with TTN right? An unconfirmed downlink regardless of frame counter should be “fire and forget”. I do see the downlink counter incrementing which is strange since it technically is a “replay” so there’s no way to filter that out on the end node.
Basically, the solution you’re suggesting is to not relax frame counters, but if that’s the case what’s the point in even having the option at all if you can’t use it with unconfirmed downlinks? Am I reading that correctly (that you cannot relax frame counters IF you’re using downlinks)?
Just guessing, but I don’t think that disabling the frame counter checks was meant to support devices that use the same counter for all their uplinks. It’s just a dirty way to (partially) support ABP devices during development, for devices that reset their counters when restarting. And even that comes with more problems to take into account. All would be “fine” if the device would increment the counters at least once between downlinks?
I’ll give that a shot and see if it “fixes” my problem for now. In the end, I do plan on moving to OTAA; however, there are some issues with LMIC and my board which prohibit using it. Great news it that I think those are being addressed. Again, thank you!
I’d not expect the downlink queue to be purged. But indeed, I’d also expect the network to recognize that it’s not a retry, so not repeat the previous downlink. That said: seems like an edge case, only happening for downlinks when the uplink counter is 1?
Thanks so much Arjan for the help. So, to really summarize this thread, I’ve tried to and failed to do the following:
ABP relaxing frame counter checks with downlinks (does not work).
OTAA with frame counter checks enabled and OTAA rejoins with downlinks (does not work).
So my last option (which I get is the “expected” implementation), use OTAA and then ABP with frame counters turned on IF I expect to use downlinks with my app. You’re probably right though with the frame counter being 1 is the possible edge case since I am scheduling the downlinks before OTAA.
Having said that, it feels like I’m a little cornered with a solution for TTN integration, but I can’t complain too much since it’s free AND easy to use, but I guess my next hardware revision will need to include a FRAM chip due to flash wear leveling. My particular hardware uses RTC wakeup from deep sleep to save on power consumption (which causes a reset - nRF52840), and so I need to now persist frame counters every time I go to sleep (which I was trying to avoid by performing OTAA re-joins).
I was going to deal with the devNOnce on my backend by re-registering the device every so often. I favored doing that on my backend as opposed to adding more code/hardware ($$) to all of my distributed nodes. Perhaps I’ll make a case on github and see how the team responds.
Messy! (And in LoRaWAN 1.1 the DevNonce needs to be incremental, so would require you to persist state anyhow.)
Persisting state, or choosing a low power sleep mode that keeps state, is really the way to go for any LoRaWAN device.
(Aside: you need to store much more state, not just the uplink counter, especially when using ADR, or when using a region that sends network settings after an OTAA Join.)
Persisting state, or choosing a low power sleep mode that keeps state, is really the way to go for any LoRaWAN device.
If you don’t me asking, how are engineers dealing with persistence for devices that go into a sleep state which requires a hard reset on wake up? FRAM? It just feels really heavy/fragile to have to persist so much state each time you make a request to the LoRaWAN server. State can get corrupted, flash wears out, specs change, and additional storage space which doesn’t wear as easily costs extra money and takes up extra space. Is this the norm for LoRaWAN? I understand persisting some state, but re-authenticating is a fairly normal process in the HTTP world (which is stateless as well). Again, thank you for the responses.
As OTAA needs a downlink, and downlinks are very expensive (as gateways cannot listen while transmitting, and gateways need to adhere to things like duty cycles as well) and fragile (the device might not receive it), this simply does not apply to LoRaWAN. Also, a join would probably use more battery power than using some sleep to preserve state in memory?
Some modules simply don’t need a lot of power to preserve state in memory. Like:
Got it. I ordered a few RAK4200 modules a week ago so that I can get out of the LoRaWAN software business all together for my app, and I’m ok with extra power consumption. It sounds like it’s the way to go rather than using the RFM95 (which requires more work, but less power consumption). Thanks Arjan.
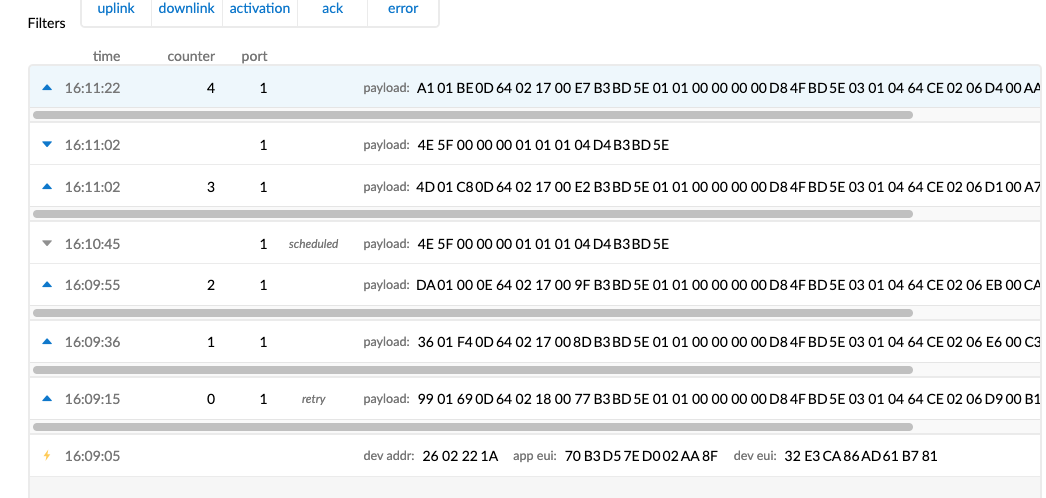
Success! I’ve been able to save enough MAC state in order to perform uplinks and downlinks between sleep! Attached a screenshot of my traffic. I’ll need to do a little bit of hardening for errors coming back from LMIC, but so far so good (with retries as needed). Thanks!