Hello everybody.
I am running a (outside) Semtech UDP Packet Forwarder gateway on raspberry pi 3B for more then a year without any noticeable problems.
Due to the migration from V2 to V3 I have moved my 2 applications to V3 and left my gateway still in V2 mode for allowing others to migrate until December 2021.
So my 2 applications are delivered now (via the packet-broker) to the v3 stack.
The migration was quite simple and everything looks ok.for many day’s… however …
I have noticed the following behavior for more the 3 times:
.x On the v3 console no data is coming in anymore from my both applications
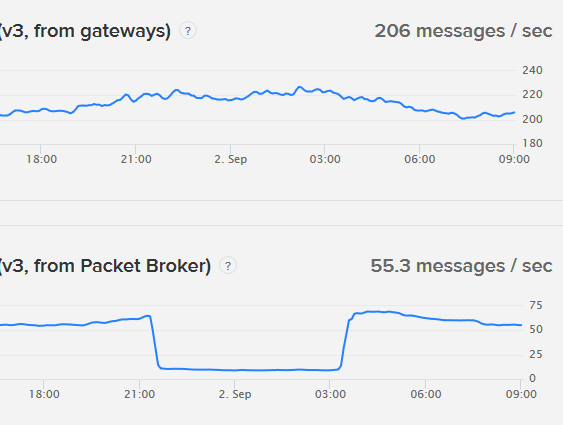
x On the status page of ttn the chart with title "Received Uplink Messages (v3, from Packet Broker) " shows a major drop (~90%) of received messages.
x After several hours (e.g.8) the number of "Received Uplink Messages (v3, from Packet Broker) " goes back to normal.
However my both applications are still dead on the ttn console.
The only way to get it working again is to manually reset the both end devices ( LoRa32U4)
In the full V2 environment it was NEVER needed to reset the end devices
At this very time (23:00 CET) such a situation looks active: (see uploaded graph)
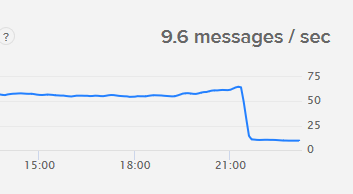
On the status page of TTN there is no incident active and everything should work smoothly, but a drop of 90% of incoming messages from the packet broker to the V3 stack looks to me as a serious problem.
Also it is not very comfortable to go to the end devices to solve such a problem by manual resetting the device to force a OTAA join again. (and the reset works only AFTER i see the graph going back to a normal level of messages /sec.) If i put full debugging on the ttn console, nothing is coming in.such a period.
On the gateway looks everything ok, lora packages are coming in during the period and are delivered ot ttn.
Does anybody else experience the same problems ? Or am i allone ?
Any advice is welcome !
thanks in advance
anton van der leun
update september2:
the broker was down for 6 hours, but this time a hard reset was not needed, as both applications came back online without manual intervention