Hi, I would like to share my experience on trying to make a very basic battery-operated sensor node running LMIC on an ESP32. It was easy to get started with the LMIC ttn-otaa example, but i’ve needed to add a few things to avoid battery drains by unforeseen events. The basic function of my sketch (via Arduino IDE), inspired by JackGruber’s deep sleep solution:
Wake-up; read sensors
Init lora radio; if available, LoadLMICFromRTC()
Queue packet with sensor data
Go into the loop with os_runloop_once()
When EV_TXCOMPLETE, SaveLMICToRTC() and go to deep sleep
[details on hardware on my blog]
When i put these nodes in the wild, their batteries were depleted in a matter of weeks. These are the improvements that i came up with, happy to receive advice.
LMIC does not automatically re-join (also reported here). The easiest solution seems to be to reboot the device after a certain (long) interval, as in this Semtech link. I re-join once per day. (as far as i could see, LMIC_setLinkCheckMode(1) did not trigger a re-join, or maybe it takes very long to trigger, 816 uplinks?)
If the join fails (e.g. gateway or server offline), i understand it is necessary to ‘back-off’ to avoid network congestion, and it is also very important to save battery power. The node sleeps extra long (1 hour) on event EV_JOIN_FAILED or EV_REJOIN_FAILED.
Maybe sometimes EV_TXCOMPLETE is never reached, so i introduced a timeout (2 minutes) to put the node to normal deep sleep.
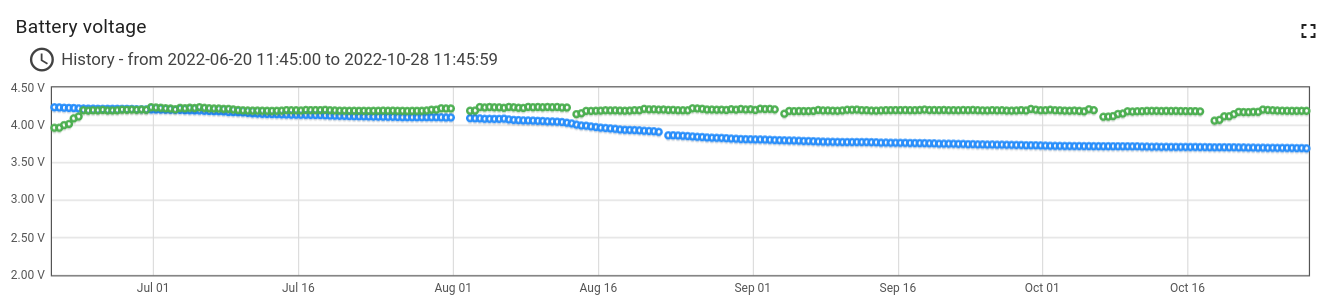
With these additions (and a watchdog timer), one node has been running for 4 months already on a (recycled) pair of 18650 cells (10 minute sending interval, 4 bytes payload, SF7). Another node has a small solar panel that keeps the battery topped up.
[more details on my blog]
I am aware of the Generic Node, and other (probably) high quality open-source nodes, but as an Arduino fan, i’d like to build something simple, robust and minimalistic, bottom-up. Any advice welcome!
Well done on getting the system running to your satisfaction… and thank you for sharing…
…but a search of the Forum will tell you this is absolutely not best practice nor the best way to handle a node.
Ideally a node should join once (for any given LNS association) with credentials then being held and retained for future use. It may be that depending on the design and resources a rejoin is needed after a major power outage - such as a battery change, etc. A watchdog function may well be engineeered to monitor node and signal behaviour and under specific conditions or concerns may then decide to trigger a rejoin or even a node re-boot with associated rejoin (if credentials not retained), but again this should be a limited number of times. Each join has an associated dev nonce and there is only a limited pool for use. Depending on the spec used - 1.02, 1.03, 1.04 etc the way these are used and any associated number increment will vary but eventually if joining frequently this pool will be exhausted and the device will not be able to rejoin, joins may also taking increasing time to effect a join - long gaps in supplying data and greater power extraction from the battery before it does something useful, with foreshortened life. The only solution once exhuasted is to delete the device from the back end and re-instate to trigger a new nonce pool…
Forum search may help you reseolve any issues you are seeing that force you to rejoin and will suggest mechanisms for limiting the need or what to do to retain credentials avoiding a rejoin…
Thanks @Jeff-UK for the explanation about dev nonce, sorry i see that had been mentioned elsewhere already. I’ve started a test with a node without forced re-joins, maybe that will already solve the periodic hangs i am seeing when the nodes were re-joining.
However, i’m still hoping to get some practical advice on how to make an LMIC node run robustly, and there is little i can find in the forum. Is it because the LMIC minimal example takes care of everything, should run perfectly forever, and any mishaps i experience are due to my hardware?
Regarding your suggestion “A watchdog function may well be engineeered to monitor node and signal behaviour and under specific conditions or concerns may then decide to trigger a rejoin or even a node re-boot with associated rejoin”, what i’m trying to find out is if LMIC implements this reliably, that’s why i’ve posted it in this category
I read about EV_LINK_DEAD, which seems like an indication that something is wrong, and could be a good candidate to trigger a node reboot with re-join, but LMIC’s own solution seems to keep trying for another 720 (=816-96) uplinks. At an interval of 10 minutes, that could take 5 days. My question is, are any professional developers using LMIC relying on this mechanism, or do you implement it differently?
Are the 2 other features i mention (back off when join_failed, timeout of txcomplete) good ideas or are there better ways to do this with LMIC?
I also found another suggestion to include a downlink command to reboot the node, forcing a re-join, is it worth adding this?
Thanks for any practical advice.
Your first challenge is the the ESP32 sleep mode is less than ideal so ends up making things complicated with holding things in non-volatile memory - saving & restoring the LMIC state isn’t obvious so with the very few solutions around they have to be tested and that takes time plus a rather intimate knowledge of LMIC & LoRaWAN.
For the rest of us using AVR or SAMD on LMIC, it’s simple enough to put the MCU to sleep, so no saving of settings is required, it wakes and carries on. If it has a battery change or runs out of solar then it just rejoins when it gets power back. But that’s rare so not an issue. I preclude STM32 for LMIC here because I don’t see much use of it, nor do I have any experience - I use LoRaMac-node on native STM code base.
A downlink to reboot the node to force a rejoin is an abstract concept - the only way a device will get the downlink is when it does an uplink and listens for an answer - and it can only do that if it has an active session, so it doesn’t need to rejoin …
As for link checks, it’s simple enough to put in some code for elapsed time or number of uplinks and do your own faux link check with a confirmed uplink and if you don’t get back an ack after a few uplinks, go for a rejoin.
The LoRaWAN spec has the link check commands but implementation varies and yes, it can seem to take a long time for it to update. The code should be doing a check ever 720 uplinks, not trying 720 once it thinks there is a problem. And then there is a whole range of back-off & retry recommendations (see TR007).
My reality is that I have several AVR LMIC devices that have been running on batteries for a few years now - I think one is on 150,000+ uplinks. The newer versions of LMIC need a bit more flash & RAM so an ATmega4808 based board is better, or a SAMD device.
Certainly is. The code overhead is minimal and it provides flexibility that can come in handy. I used the mechanism to move multiple devices from TTN V2 to V3 before the migration tools were available.
Whilst you can get a fairly low deep sleep current if your ESP32 module has a decent low Q regulator (and not many do) and does not have one of the common USB to Serial devices on board (and not many do), the ESP32 in deep sleep basically starts as cold when it wakes up. Sure you can save variables in the RTC RAM, but the hardware such as the SPI interface to the LoRa device needs to be re-initialsed as if from cold, unless I am missing something obvious.
thanks @descartes for the feedback and clarification. one reason i like to use the ESP32 is that it allows me to do OTA firmware updates: i send a downlink to enable wifi, the node connects to my phone hotspot, and i use the arduino ide to push the new firmware. handy when you can get within a couple of meters of the node.
i will implement the downlink reset as you suggest @kersing; i just had a situation where i wanted to adjust the ADR margin (via console) but as far as i understand the new mac-setting only works after a new join.