Wow, that’s a messy post. I see duplicate details in the screenshots, and what are we even looking at? Most looks like a downlink trace?
Also, is this about traffic that, though shown in the gateway Traffic, did not arrive in your actual application? If so: how is that application getting its data from TTN? If that is not using MQTT: what does a command line MQTT client receive? How does a trace of dropped uplinks compare to uplinks that are handled correctly?
(Just to be sure: if you’re only looking at the Data page in TTN Console, then that often stops showing data without any clear reason. So: look at what your actual application is receiving. Or enable the Data Storage integration for debugging.)
What are the other details of the uplink that triggered that downlink? The one shown in the screenshot shows FCntUp 6. But the downlink says reason: initial, so seems to be a US915 initial ADR command, which should only be sent once in the lifetime of an ABP device, emphasis mine:
There are a several moments when an ADR request is scheduled or sent:
- The initial ADR Request (for US915 and AU915). This is sent immediately after join and is mainly used to set the channel mask of the device. This one is a bit tricky, because we don’t have enough measurements for setting an accurate data rate. To avoid silencing the device, we use an extra “buffer” of a few dB here. This request is only needed with pre-LoRaWAN 1.1 on our v2 stack. With LoRaWAN 1.1 devices on our v3 stack, we can set the channel mask in the JoinAccept message. ABP devices pre-LoRaWAN 1.1 will only get this message once, if they reset after that, they won’t get the message again; this issue is also solved by LoRaWAN 1.1.
However, now that gateway traffic is (partly) routed through V3 components, maybe that’s no longer only sent once.
Do you see downlinks for every uplink?
Yes, all as expected. (The log entry duplicates: 1 actually indicates there is only a single occurrence, not two.)
So, the same DevAddr is used by 3 ABP devices in your region. After 2 MIC checks it found your device, hence does not need to check the 3rd device as well. All just as expected, as explained in one of the links in my earlier answers. (This is not a problem for you, as you wrote that all your devices have a different DevAddr along with your single NwkSKey. So, the other 2 devices are someone else’s ABP devices, using a different NwkSKey.)
I still think that the key question is: do you see the missing uplinks in the gateway’s Traffic? So, do you still see a device’s traffic in the gateway after a device stopped working after 10 days?
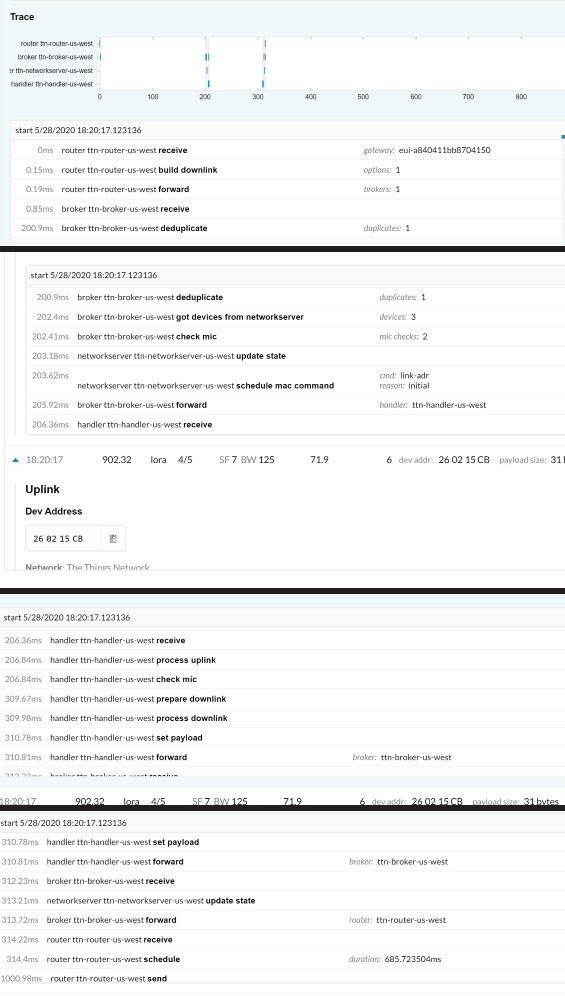
 , I will put more work in making my posts. I just got really excited cause I haven’t seen a downlink (yes it’s a downlink trace) in a long time. The uplink associated with this downlink was received by the TTN, so one device broke through a 5 day period of silence.
, I will put more work in making my posts. I just got really excited cause I haven’t seen a downlink (yes it’s a downlink trace) in a long time. The uplink associated with this downlink was received by the TTN, so one device broke through a 5 day period of silence.