Dear community,
from time to time technology fails us. Whenever situations like this happen with the backend someone from TTI will fix it. If this happens with our gateways and infrastructure we do the service.
From what I can collect from my short history with TTN is that the main entry points for alerting are the Slack #ops channel and this forum. Depending on to me unknown facts someone will fix the backend situation in different time frames.These incidents are then transparently reported on the TTN status page.
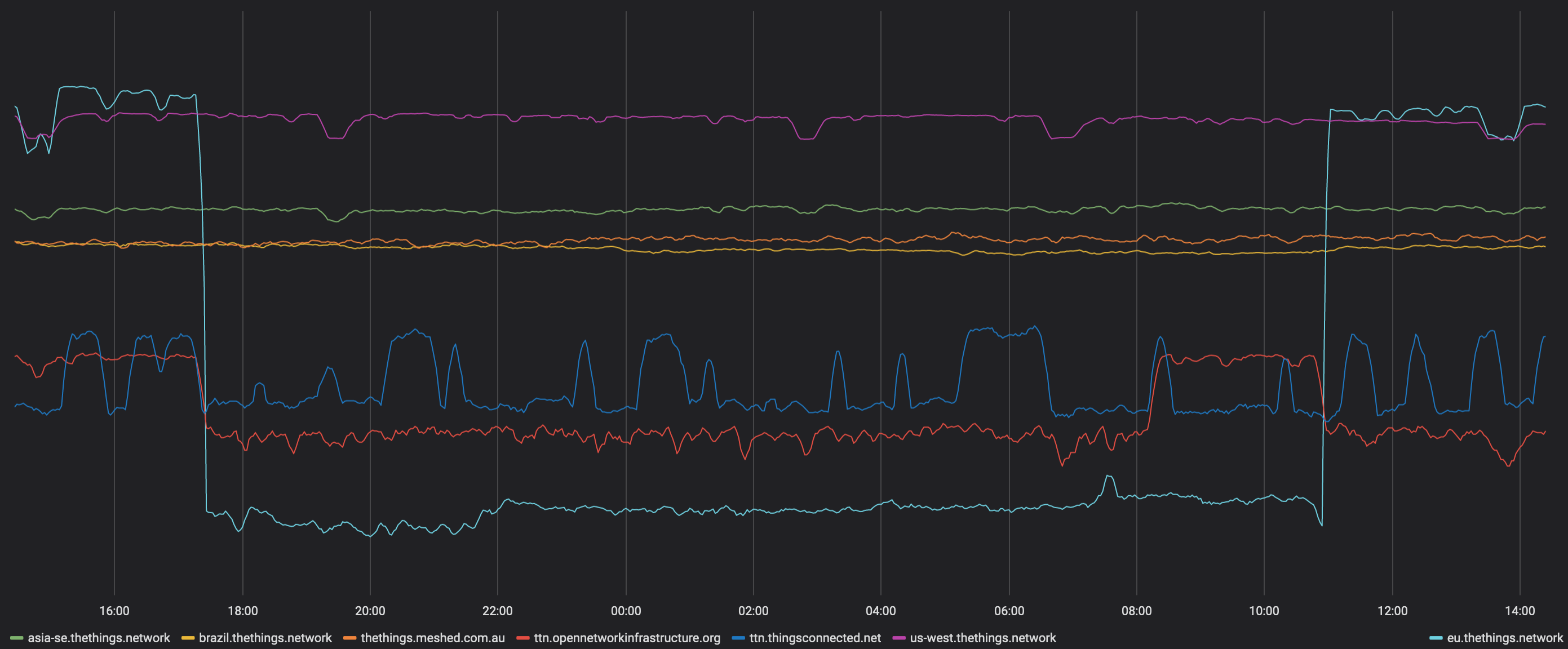
Based on the recent incident starting 09/14/19 where more than 10hrs no data was received/forwarded I would like to start collecting ideas how that timeframe of no information and fixing could be decreased.
(I will post my personal opinion in a follow up.)
Please follow the forum guidelines/ruleset. Use nonviolent communication where ever possible.
So just that you know before: I can not deal very well with no information situations. I have a strong need for clarity and more a “We need to do something” type of guy than “Ok lets wait”.
The recent incident was reported here and in the Slack #ops channel and IamBatman fixed it. I assume it took him 5 minutes, based on his first reaction in the channel and the messages comming in again.
TTN is provided “as is” there is no SLA (service level agreement). We all know this and by joining also agreed to this. TTI people probably are on shifts to provide the service they can. Even on weekends and holidays. Thank you for your service.
I assume that there are certain errors classes that are easily identified by trained and trusted humans and can be fixed with a pretedermined set of options (e.g. restarting a service). If we the community want the service to be more stable (I do!) then I think we as a community need to invest.
I can imagine a TTN watchtower group that consists of community people willing to give part of their day to watch over TTN. If they then have a little bit of training (quality assurance!) and the possibility to restart services (e.g. by a TTI provided access) they could fix maybe a lot of incidents fast and “escalate” the other to TTI.
I see this as a very logic step in the growth process of TTN and being so in line with the manifest that inspired us all:
We believe that this power should not be restricted to a few people, companies or nations. Instead this should be distributed over as many people as possible without the possibility to be taken away by anyone.
First of all, I’m glad that @KrishnaIyerEaswaran2 managed to resolve this particular incident, and I would like to thank him for taking care of it. I haven’t spoken to him about what exactly was wrong and what he did to resolve it. We’ll discuss that tomorrow and update the incident page with some details.
We understand that many here are relying on the public community network services being available at all times, and I think we can all agree that outages like this one already don’t happen often. Since the public community network doesn’t have an SLA, our internal on-call system only alerts the team about incidents with the public community network during working hours, and not at night or during weekends. Outside working hours, there’s often someone from the team available to take action, but this time none of us was available for a long time.
The Things Network’s backend (v2) was designed with decentralization in mind. The public community network consists of multiple clusters worldwide, some of them operated by The Things Industries, others operated by partners such as Meshed, Switch and Digital Catapult. As a bonus, there is (usually) traffic exchange between the regions. The idea was that this decentralization allows us to operate a global network that doesn’t rely on a single party (TTI) for everything. So far that model worked quite well, and also with the recent incident with our EU cluster, we can see that other clusters were still fully operational.
I’m pretty sure that giving external people access to TTI-hosted clusters isn’t going to happen. Instead our goal is - and always has been - to involve more operators in the public community network. We believe that large and active communities should be able to operate their own clusters instead of relying on TTI-hosted clusters. Unfortunately our v2 implementation doesn’t properly deal with unreliable or malicious operators (we learned that the hard way), and we decided to stop adding partner-operated clusters. With v3 this is going to be possible again, and we hope to involve communities in hosting their own clusters.
I know I don’t have to watch as my automated monitoring provides that information readily. Yesterday at 17:15 CEST it reported there was a problem. Reported things were up and running again this morning within 5 minutes of the issue being fixed.
The only thing I need to do when I get monitoring messages is to check if the monitoring might have an issue but that happened only once over a 3 year period.
That is interesting because I inquired about what would be needed to implement this for our Dutch community at least 3 times to be told there is no need as TTN covers NL quite adequately.
Hmmm, speaking to different core team members at this years TTN conference regarding this my take on the answers was that I was discouraged (again) as there is no need. Did I interpret the responses that badly???
@kersing’s quote of my message is missing quite an important bit of context:
With our current v2 infrastructure, we indeed need to avoid adding clusters (specifically broker+networkserver combinations) if not needed. In regions that are already being served by our existing infrastructure, there is indeed no real need, but more importantly, it will lower the quality of service. This is a technical problem with v2, and not because we don’t want it.
I agree that it would be good to discuss the future of operating public community network clusters, and we indeed don’t need to wait for The Things Conference with that.
For me the failures are not the biggest problem, I know TTN is provided “as is” and depends on some hardworking volunteers solving the failures. But if I am experimenting with my gateway or nodes and I encounter a problem, I would like to be able to exclude that something is wrong with the TTN services. More than once it took me many frustrating hours to figure out what was wrong with my nodes or gateway while it later turned out that there was a failure at TTN, often a failure that was not reported on #OPS or on the status page. The status page sometimes even reported that there were no problems while there certainly were issues. So a really up-to-date status report would be highly appreciated and would save me a lot of frustration.
I mean, addressing the growth of the community / network and the problems in general as we all can see this year.
A presentation of ideas and future implementations how to cope ?
A more or less automated actual status page with input from devices worldwide combined with operator data for example would be very usefull.
What can we, as community, do to help improve… think we need more guidance from TTi were to start
I presume TTI benefits from 24/7 engineer alerts and possibly out of hours fixes.
One idea for the list might be to treat TTN users as a TTI customer and figure out a cost of providing some sort of SLA on a paid basis. I am sure there are enough of us on TTN to make a regular ‘donation’ to make this business model work. At the very least, such an SLA would have alerted an TTI engineer to the 15+ hour complete outage issue (which in this case, I presume, would have been a simple fix).
The problem, no doubt, will be the scope of such a SLA in the context of a ‘as is’ free service.
I’m thinking ‘critical issues only’ at this stage.
To be honest, I think the only really viable solution is going to be a two-level one, where someone with a fleet of gateways manages their own network server with whatever level of reliability effort they require, and anything unknown to that then gets bumped up to a regional server that handles “roaming” along with individually owned gateways not having their own serving infrastructure.
An organization who invests in putting up a decent number gateways typically has an application need that means it isn’t going to be able to justify depending on an external service with no SLA in a situation where the failure of that can take out even purely local usage.
My general sense is that what’s missing to make this work, is an ability for a gateway (or an intermediate server proxying for many) to indicate back to a server that it won’t be able to accept a transmit request, because it is already busy transmitting something else at that timeslot. Lengthening the standard RX1 delay would greatly increase flexibility for “who is going to send it” negotiations, with little obvious downside.
Ultimately, if TTN can’t be architected in a way that allows local and fleet self-reliance, the result is likely to be lots of uncoordinated private networks serving only the needs of those paying for the infrastructure.
Given the number of TTN users (many of which will be businesses) I would expect donations to exceed the actual TTI cost, building up a buffer. Until TTI throw some figures at this it’s difficult to say (how cash strapped are they) but £5-10/month/donation would seem reasonable plus some [more] good will from TTI.
I am sure TTI do WANT to keep things running smoothly as TTN is a good test platform for them and is a good news story for their TTI sales.
Anyway, just a thought as it would bring a basic SLA to the TTN platform.
As someone who manages their own cluster (Australia), I watched the comments unfold in the #ops channel yesterday. It was frustrating to watch, even though our region wasn’t even the one impacted.
On one hand I can’t work out how it can take 15+ hours for TTI to respond to a problem of this magnitude when #ops was buzzing with comments every few minutes. On the other hand, TTI staff are entitled to enjoy their weekend uninterrupted by work.
Even though TTN is ultimately provided to us as a best effort free service, for some of us it’s become part of what we do for a living. At a country-wide level for some of you it will make sense to invest in the infrastructure and services required to manage your own cluster (when V3 becomes available).
For Australia this has worked well. We have become largely immune to the issues that affect the global network, mainly because we’re smaller and it’s more manageable, but mostly because we can decide how and when to respond to issues that arise and we’re available in our own timezone. For the most part we can fix the issues ourselves. (Occasionally though, we can’t, and we have had long outages too)
But it seems to me there was one simple thing that could have made yesterday’s outage more tolerable for those affected… acknowledgement. Just something notifying everyone that TTI are aware of the problem. It could be an automated Slack message, a status page update, a simple “we’re aware of a problem” message. That would make “best effort” even better
What about the status pages? As far as I could see https://status.thethings.network/ did not show any change during the latest incident. That was one reason for irritation…
As someone who used to provide 24\7 support for large computer networks, I can fully understand why it took TTI that long to respond to a problem for which they had no SLA.
Once those who are responsible for the 24\7 support for TTI start dealing with TTN issues, because its seen as a good thing to do, the response becomes expected by the community (for free) even though its outside of the SLA.
Now if I was being paid (in my old job) to look after a network, then indeed I kept an eye on systems, but I was careful not to deal with issues for which there was no SLA and for which I was not being paid. Is that just mean, or practical ?
If the TTI guys were to provide a 24\7 SLA for TTN, I guess someone would have to pay for that service.
 Add it to Reading and all the pending Q4 regional Confs!
Add it to Reading and all the pending Q4 regional Confs! 