Hi there,
I tried to migrate one of my LHT65 to the V3 Stack: Created the device in the V3 Backend, issued a Reset via 04FF as a Downlink, waited until the Downlink has been sent, deleted the device in the V2 backend. Unfortunately this doesn’t work out as expected: the device isn’t joining in V3, actually I think it hasn’t rebooted.
Does anybody know, if it tries to join, if it isn’t receiving downlinks any more? After 1 day nothing changed (okay, that’s 1 downlink - probably I just have to wait longer).
I’m very new to LORA but picked up some devices for the fun of it - a LHT65 amongst them. I have migrated my GW and several devices to v3, and found I had to push the activation button on the LHT65 for it to join v3. Have you tried that?
With another device I’ve been successful after one night.
I follwed Hylkes manual Migrating OTAA Devices from V2 to V3 - V2 to V3 Upgrade / Migrating Devices to V3 - The Things Network and didn’t delete the device but changed the App-Key. So I’ve been able to see what is happening. The LHT didn’t react to the Downlink which should initiate the reboot. So it took 10 hours and 40 Downlinks until it rebooted and joined V3 without any problems. Firmware on my LHTs is 1.3
I’ll try that with a few other devices and update the first post.
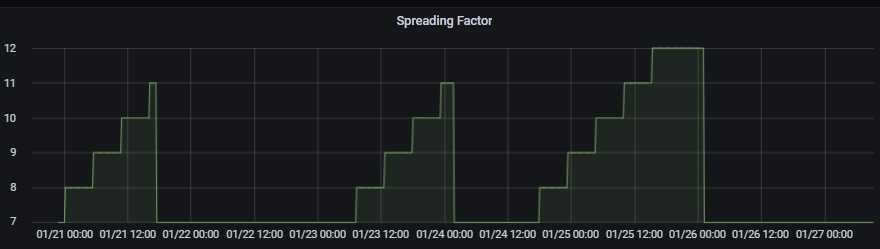
i also tried to move LHT65 from V2 to V3. Unfortunatly it seems ADR is not working anymore.
The LHT is stuck at SF12. Does anyone have a similar issue.
Is it possible, that there is a change in the RX Windows that are used by ADR?
Thank you all
Is it possible, that there is a change in the RX Windows that are used by ADR?
There definitely is, indeed!
If you use OTAA then when joining to the new network that would be communicated automatically.
If you use ABP you have to manually set the RX1 delay to 5 seconds instead of 1.
Also with TTN V3 it is absolutely critical that a node correctly support not only downlinks, but also that it correctly process and respond to MAC commands.
Isn’t that more or less what ADR is supposed to do?
Could you clarify what the actual problem was?
Typically it is the network that commands dialing up the speed (dialing down the SF) while the node failing to receive anything for long periods of time would gradually go the other way in desperation.
Of course is ADR supposed to adjust the data rate to the best SF. In my case it worked the other way round. Initial SF has been set to 7 and ADR increased it to 11 or 12. The devices (had this problem with 3 LHT65s) haven’t been moved and were in close proximity to one or more gateways, maximum 200m. My expectation was that they stay at SF7. As of this I disabled ADR and set the SF static.
Coming back to topic: Probably the LHT65s suffer from a very bad reception or a very short and hard-coded RX Window? In my case, ADR has been problematic and when migirating to V3 I had to send many many downlinks until they rebooted. (V 1.3, so quite an old firmware)
That would likely indicate your downlink path is not working correctly.
It’s critically important to note that TTN V3 makes proper downlink support - and proper handling of MAC commands absolutely mandatory - even if you chose to forgo ADR, you must not put a node on TTN V3 unless downlinks actually work.
Coming back to topic: Probably the LHT65s suffer from a very bad reception or a very short and hard-coded RX Window?
Probably mis-timed RX windows. TTN V3 changes the RX1 delay from 1 second to 5, but I suspect the actual issue is that your particular configuration fails to reliably achieve the receive window timing it is set for.
Nothing special here. Vanilla LHT65, Raspberry Pi with IMST- iC880A-SPI and the (quite old) ttn-zh setup. Last will change when the gateway is moved to v3. What could be problematic is a quite high internet latency, but even 300ms shouldn’t break it.
You claimed ADR didn’t work and that you suspect receive problems, which strongly suggests that “normal” for these nodes is actually “broken” - and that’s going to cause problems for the V3 network if you register them there.
Not just problems for you: if your nodes don’t receive downlinks, that’s going to cause problems for other users of the network, too, since the network will keep sending them over and over and over.
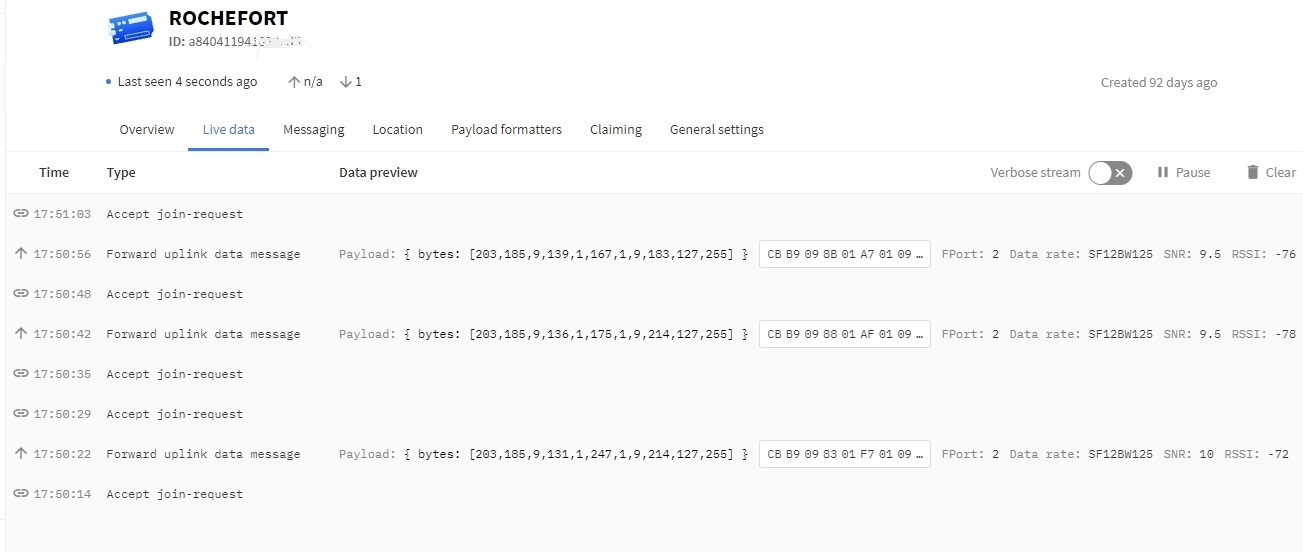
I have a Dragino LHT65 which is connected to V2. I modified the appkey, I turned it off and restarted so that it connects to V3, it connects well and I have the data from the sensors, the problem is that it sends messages all about 20 seconds while I put a 5-minute measurement step. I send downlinks to modify this but nothing changes. After each sending of message, I again have a message “Accept join - request” (see attached image)
In the manual you can find how to connect a serial port to the unit using the magnetic connector included in the box. There are instructions on how to use the serial port to set parameters in the documentation as well.
The reset might be caused by the downlink. When the device receives some new settings it resets to activate that new setting.
What is the exact message you are sending to the device?