We are just about to start our first larger application with LoRaWan, but still are testing the system. Our setup:
- 3 gateways (different typres) in separate spaces
- Some commercial nodes, e.g. one “theThingsNode”, some LMIC-Nodes for testing
- different ranges, but all nodes still running on SF7
We are using node-red to receive packets from the discovery-Server and forward them to Thingsboard.
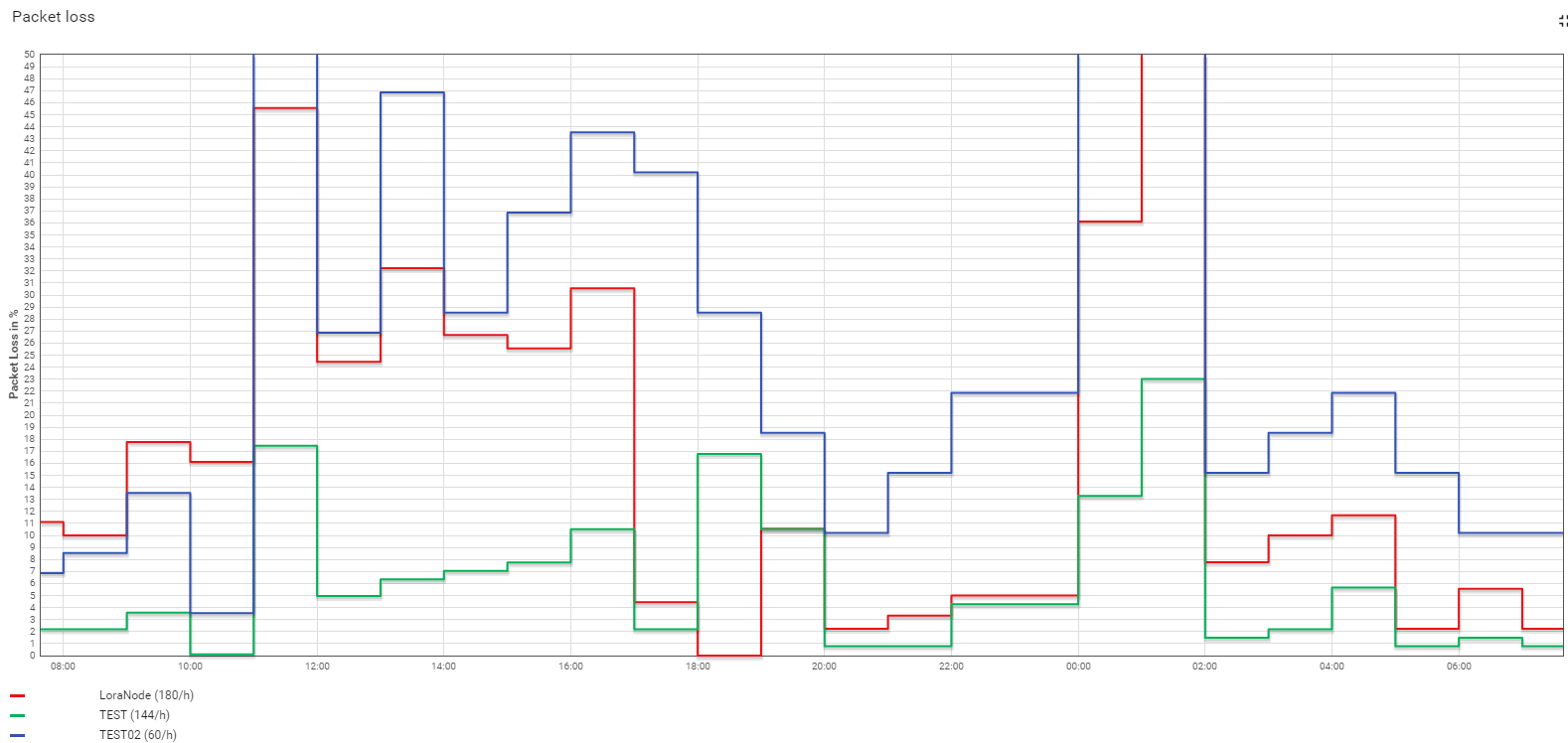
Overall results are good, but we are still facing a packet loss rate. As we are not pretty sure about the reasons we are doing some investigations. Main question is also, if/how can we reduce the loss rate?
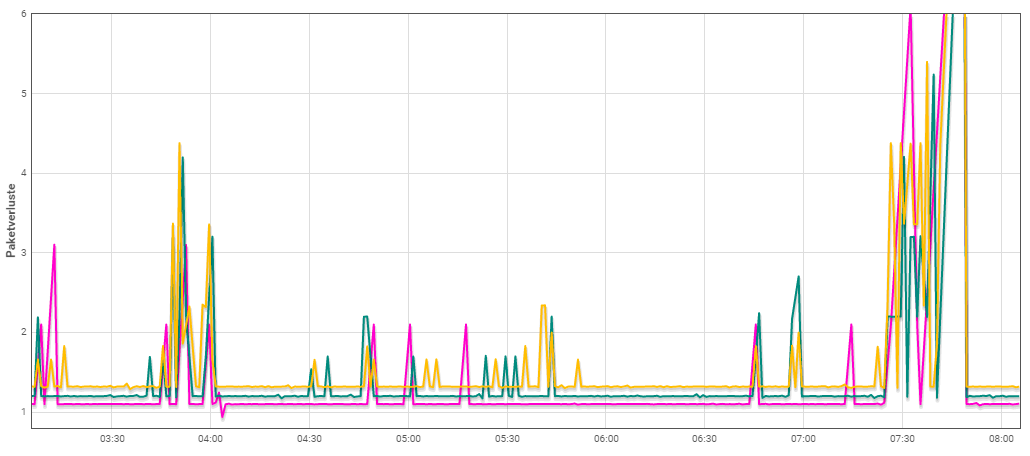
Single packet loss is not so critical, but we also see some clusters of lost messages. The following protocol shows the time difference between two received messages and the packet loss evaluated from the node counters. Most of the time, there is only a single loss, but frequently we also have up to 7 packets successively lost.
Sure, the packet rate is high (one message every 20s for test purpose), but things are similar with lower rates. There are hours without a single loss, but most of the time it is like in the following protocol. Average loss rate is between 2 - 10%, but we have also times with 25% loss.
Any suggestions, how to analyze the situation? As far As we can see there is no downlink on the gateway.
Here are some logs:
{"bat":4.69,"dt":20.307,"time":"21:14:36"}
{"bat":4.7,"dt":40.754,"lost":1,"time":"21:15:17"}
{"bat":4.7,"dt":20.433,"time":"21:15:37"}
{"bat":4.7,"dt":20.713,"time":"21:15:58"}
{"bat":4.71,"dt":20.021,"time":"21:16:18"}
{"bat":4.71,"dt":20.385,"time":"21:16:38"}
{"bat":4.7,"dt":20.415,"time":"21:16:59"}
{"bat":4.71,"dt":20.346,"time":"21:17:19"}
{"bat":4.7,"dt":20.387,"time":"21:17:39"}
{"bat":4.7,"dt":20.4,"time":"21:18:00"}
{"bat":4.7,"dt":20.416,"time":"21:18:20"}
{"bat":4.69,"dt":20.809,"time":"21:18:41"}
{"bat":4.69,"dt":20.006,"time":"21:19:01"}
{"bat":4.69,"dt":20.461,"time":"21:19:21"}
{"bat":4.7,"dt":20.297,"time":"21:19:42"}
{"bat":4.7,"dt":20.359,"time":"21:20:02"}
{"bat":4.7,"dt":20.375,"time":"21:20:22"}
{"bat":4.69,"dt":20.435,"time":"21:20:43"}
{"bat":4.7,"dt":20.368,"time":"21:21:03"}
{"bat":4.7,"dt":20.426,"time":"21:21:24"}
{"bat":4.69,"dt":20.507,"time":"21:21:44"}
{"bat":4.71,"dt":20.318,"time":"21:22:05"}
{"bat":4.71,"dt":20.309,"time":"21:22:25"}
{"bat":4.71,"dt":20.42,"time":"21:22:45"}
{"bat":4.69,"dt":20.405,"time":"21:23:06"}
{"bat":4.7,"dt":20.458,"time":"21:23:26"}
{"bat":4.69,"dt":20.406,"time":"21:23:47"}
{"bat":4.69,"dt":20.315,"time":"21:24:07"}
{"bat":4.7,"dt":20.393,"time":"21:24:27"}
{"bat":4.71,"dt":20.401,"time":"21:24:48"}
{"bat":4.71,"dt":20.33,"time":"21:25:08"}
{"bat":4.7,"dt":20.733,"time":"21:25:29"}
{"bat":4.71,"dt":20.055,"time":"21:25:49"}
{"bat":4.69,"dt":20.437,"time":"21:26:09"}
{"bat":4.71,"dt":40.953,"lost":1,"time":"21:26:50"}
{"bat":4.69,"dt":20.25,"time":"21:27:10"}
{"bat":4.69,"dt":20.379,"time":"21:27:31"}
{"bat":4.71,"dt":20.367,"time":"21:27:51"}
{"bat":4.7,"dt":20.378,"time":"21:28:12"}
{"bat":4.7,"dt":20.381,"time":"21:28:32"}
{"bat":4.71,"dt":20.642,"time":"21:28:53"}
{"bat":4.69,"dt":20.13,"time":"21:29:13"}
{"bat":4.71,"dt":40.857,"lost":1,"time":"21:29:54"}
{"bat":4.7,"dt":40.746,"lost":1,"time":"21:30:34"}
{"bat":4.7,"dt":40.745,"lost":1,"time":"21:31:15"}
{"bat":4.69,"dt":20.474,"time":"21:31:35"}
{"bat":4.7,"dt":20.854,"time":"21:31:56"}
{"bat":4.69,"dt":19.961,"time":"21:32:16"}
{"bat":4.69,"dt":20.283,"time":"21:32:37"}
{"bat":4.71,"dt":20.463,"time":"21:32:57"}
{"bat":4.71,"dt":20.3,"time":"21:33:17"}
{"bat":4.7,"dt":20.451,"time":"21:33:38"}
{"bat":4.69,"dt":20.425,"time":"21:33:58"}
{"bat":4.7,"dt":20.323,"time":"21:34:19"}
{"bat":4.71,"dt":20.366,"time":"21:34:39"}
{"bat":4.69,"dt":61.503,"lost":2,"time":"21:35:40"}
{"bat":4.71,"dt":20.425,"time":"21:36:01"}
{"bat":4.71,"dt":20.109,"time":"21:36:21"}
{"bat":4.71,"dt":20.313,"time":"21:36:41"}
{"bat":4.7,"dt":40.902,"lost":1,"time":"21:37:22"}
{"bat":4.69,"dt":20.379,"time":"21:37:43"}
{"bat":4.71,"dt":20.309,"time":"21:38:03"}
{"bat":4.71,"dt":20.362,"time":"21:38:23"}
{"bat":4.69,"dt":40.86,"lost":1,"time":"21:39:04"}
{"bat":4.71,"dt":40.726,"lost":1,"time":"21:39:45"}
{"bat":4.71,"dt":20.442,"time":"21:40:05"}
{"bat":4.7,"dt":20.329,"time":"21:40:26"}
{"bat":4.71,"dt":20.408,"time":"21:40:46"}
{"bat":4.7,"dt":20.428,"time":"21:41:06"}
{"bat":4.69,"dt":20.865,"time":"21:41:27"}
{"bat":4.69,"dt":19.94,"time":"21:41:47"}
{"bat":4.71,"dt":20.328,"time":"21:42:08"}
{"bat":4.7,"dt":20.551,"time":"21:42:28"}
{"bat":4.71,"dt":20.807,"time":"21:42:49"}
{"bat":4.71,"dt":19.808,"time":"21:43:09"}
{"bat":4.69,"dt":20.508,"time":"21:43:29"}
{"bat":4.71,"dt":20.306,"time":"21:43:50"}
{"bat":4.69,"dt":20.376,"time":"21:44:10"}
{"bat":4.7,"dt":20.402,"time":"21:44:30"}
{"bat":4.71,"dt":20.558,"time":"21:44:51"}
{"bat":4.7,"dt":20.203,"time":"21:45:11"}
{"bat":4.7,"dt":20.409,"time":"21:45:31"}
{"bat":4.7,"dt":20.36,"time":"21:45:52"}
{"bat":4.7,"dt":20.383,"time":"21:46:12"}
{"bat":4.71,"dt":20.424,"time":"21:46:33"}
{"bat":4.71,"dt":20.668,"time":"21:46:53"}
{"bat":4.69,"dt":20.09,"time":"21:47:13"}
{"bat":4.71,"dt":20.381,"time":"21:47:34"}
{"bat":4.71,"dt":20.577,"time":"21:47:54"}
{"bat":4.69,"dt":20.202,"time":"21:48:15"}
{"bat":4.69,"dt":20.398,"time":"21:48:35"}
{"bat":4.7,"dt":40.778,"lost":1,"time":"21:49:16"}
{"bat":4.71,"dt":20.434,"time":"21:49:36"}
{"bat":4.71,"dt":20.369,"time":"21:49:57"}
{"bat":4.7,"dt":20.389,"time":"21:50:17"}
{"bat":4.7,"dt":20.425,"time":"21:50:37"}
{"bat":4.69,"dt":20.457,"time":"21:50:58"}
{"bat":4.7,"dt":20.283,"time":"21:51:18"}
{"bat":4.7,"dt":20.415,"time":"21:51:39"}
{"bat":4.69,"dt":40.776,"lost":1,"time":"21:52:19"}
{"bat":4.7,"dt":20.369,"time":"21:52:40"}
{"bat":4.71,"dt":20.402,"time":"21:53:00"}
{"bat":4.69,"dt":20.439,"time":"21:53:20"}
{"bat":4.7,"dt":20.545,"time":"21:53:41"}
{"bat":4.7,"dt":20.373,"time":"21:54:01"}
{"bat":4.71,"dt":20.206,"time":"21:54:22"}
{"bat":4.69,"dt":20.408,"time":"21:54:42"}
{"bat":4.7,"dt":20.383,"time":"21:55:02"}
{"bat":4.71,"dt":20.471,"time":"21:55:23"}
{"bat":4.71,"dt":20.321,"time":"21:55:43"}
{"bat":4.71,"dt":40.796,"lost":1,"time":"21:56:24"}
{"bat":4.71,"dt":20.531,"time":"21:56:45"}
{"bat":4.71,"dt":20.275,"time":"21:57:05"}
{"bat":4.71,"dt":20.4,"time":"21:57:25"}
{"bat":4.71,"dt":20.389,"time":"21:57:46"}
{"bat":4.71,"dt":20.405,"time":"21:58:06"}
{"bat":4.71,"dt":20.358,"time":"21:58:26"}
{"bat":4.7,"dt":20.412,"time":"21:58:47"}
{"bat":4.7,"dt":20.378,"time":"21:59:07"}
{"bat":4.71,"dt":20.597,"time":"21:59:28"}
{"bat":4.71,"dt":20.169,"time":"21:59:48"}
{"bat":4.7,"dt":81.6,"lost":3,"time":"22:01:10"}
{"bat":4.71,"dt":20.403,"time":"22:01:30"}
{"bat":4.7,"dt":20.502,"time":"22:01:50"}
{"bat":4.7,"dt":20.212,"time":"22:02:11"}
{"bat":4.69,"dt":20.418,"time":"22:02:31"}
{"bat":4.71,"dt":20.6,"time":"22:02:52"}
{"bat":4.7,"dt":20.161,"time":"22:03:12"}
{"bat":4.7,"dt":20.39,"time":"22:03:32"}
{"bat":4.7,"dt":20.481,"time":"22:03:53"}
{"bat":4.69,"dt":20.312,"time":"22:04:13"}
{"bat":4.71,"dt":20.426,"time":"22:04:33"}
{"bat":4.71,"dt":20.656,"time":"22:04:54"}
 even if sometimes the TTIG is not (yet!)
even if sometimes the TTIG is not (yet!)
