Sounds possible. I could try to have a look at the LoRa power supply with the oscilloscope. This revision of the T-Beam board has some mighty multi-purpose AXP192 power management chip on it, the big chip between display and antenna with nearly as much pins as the µC, which is covered by the display. Who knows, what its output looks like…
Another fun fact that might affect/help your testing of downlinks transmitted by remote gateways, after the device has joined: (at least) in the EU868 frequency plan, a downlink in RX2 uses SF9, regardless what SF was used in the uplink. And that uses an increased power:
This does not apply to the OTAA Join Accept (as at that point the device does not yet know about the TTN-specific settings, which it actually gets in the data of that very Join Accept). But after joining, or when using ABP, you might turn off the close-by gateway, schedule a downlink in TTN Console, and transmit a SF11 or SF12 uplink to increase the chance that TTN will tell the remote gateway to use RX2 with SF9 and a higher transmission power for a downlink.
I’ve no idea of any of the above is useful for debugging the topic at hand. However, testing for RX2 is good anyway!
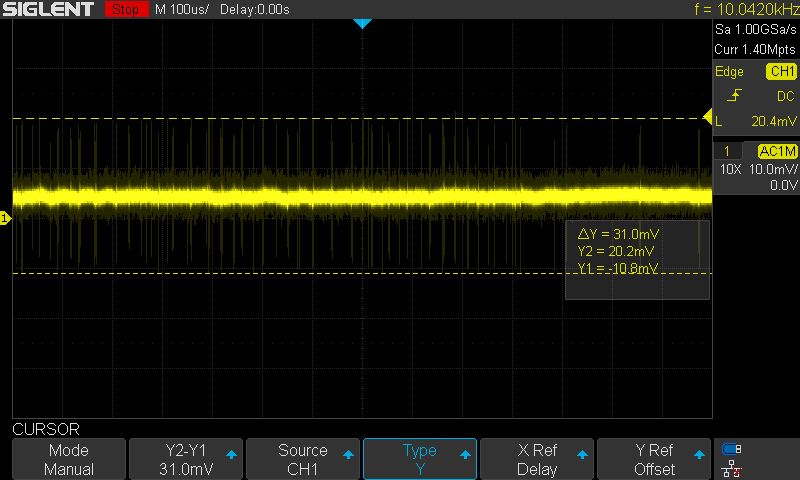
So, this is the noise on the 3.3 V supply voltage of the LoRa module:
Lots of bursts of spikes with at least 30 mV peak-peak.
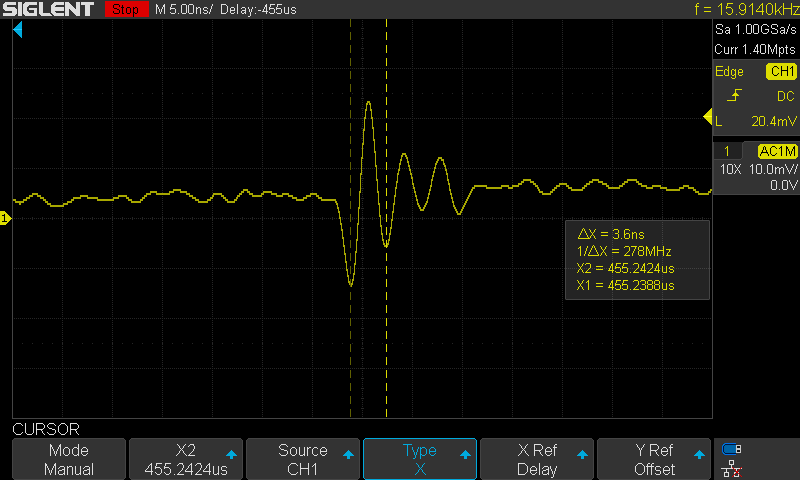
On spike zoomed in:
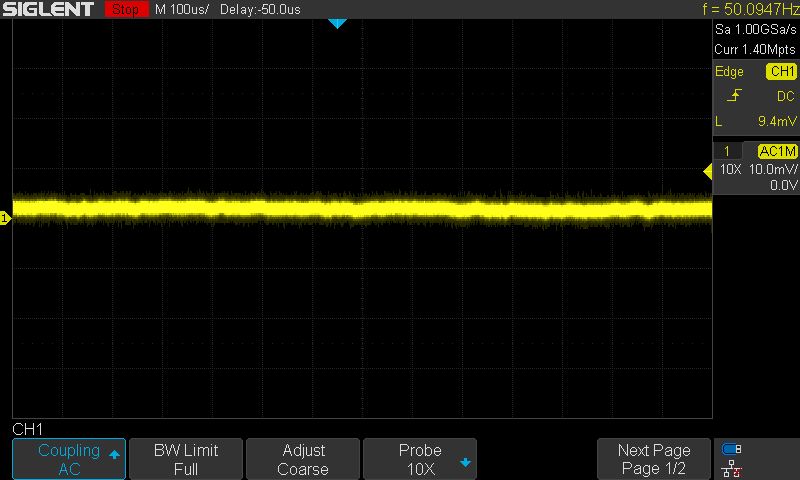
And this is with a 100 nF capacitor soldered directly to the power supply pins:
Much better
I have to stop the modifications before doing some more testing, now. Otherwise I won’t know what was the cause.
I have to say my first guess is not that local digital noise is your problem - I mentioned that with regard to the antenna reciprocity question, but don’t mean to encourage getting too sidetracked.
My actual suspicion is that some software issue, either in the node or on the infrastructure side, is meaning that you aren’t ending up with a LoRa radio transmitting and receiving with compatible settings at the same exact time.
The t-beam now displays RSSI and SNR for all downlink messages. Unfortunately, I don’t know how accurate the readings from the HPD13A registers on this board are. I used the conversion from the SX1276 data-sheet, since it’s a clone and I did not find a separate data-sheet. This does not take board specifica into account. The LMIC lib itself seems to contain some hardcoded conversions for RSSI, which do match for this chip.
I also added some shielding to the board. With this, I was able to get some successful joins at locations, where it did never work before.
The MQTT messages on my mobile phone were of great help!
Tests:
My TTIG off, so only the other GW was within reach. Joins were possible, but the success rate was 50% at best. It almost always received the join requests (visible in MQTT app log), but the device did not always receive the response. Even when I was only some hundred meters away, only about every second attempt succeeded.
The RSSI/SNR values at the GW were always better than those displayed on my device. Some samples:
location A: GW -108/8 vs. dev -112/4
location B: GW -72/12 vs. dev -82/7.5
My TTIG on, the device in the same house. I saw the join accepts coming from my GW. Joins were almost always successful, only sometimes the responses were not visible on my GW traffic log. RSSI/SNR about GW -68/10 vs. dev -80/9.
I tested with a second T-Beam, same revision, also with shielding. The behavior and RSSI/SNR readings were not much different.
Looks like a mixture of multiple issues for me:
My t-beam still has some problems with the other GW, even if RSSI and SNR are very high. Reason unknown, SW/HW/timing on device or other GW or …
My t-beam has only rarely join problems with the TTIG, if it is close to it.
The t-beam seems to have some issues on the receiving side, which can slightly be improved by additional shielding.
The other GW seems to be more sensitive than my TTIG with the internal antenna, so the problems start not too far away from my TTIG.
For tracking/mapping, I could simply switch to ABP and all problems will be gone because there will be no downlinks any more, then.
When I find the time for it, I’d like to do some tests with an interrupt based lib variant. Timing looks like a likely cause for me.
Were you able to determine if a join accept was generated? LMiC for example likes to randomly guess for a join nonce, and if it hits one that’s been used before, no accept will be generated until it increments to a not previously used value. Especially if your RNG is not very random, the more tests you run, the more likely it is that it will take some time to get to fresh values.
I’d like to do some tests with an interrupt based lib variant
It’s not entirely clear how that would help, unless you mean that you’d use a slightly less than one second hardware timer to enter receive mode the correct duration of time after transmitting.
Even if you are polling for the transmit complete, you should be able to poll rapidly enough to to notice it with low latency (just don’t do something like print the polled status - that would likely cost time)
Another thought/line of enquiry… what do you know about the remote GW? As has been suggested earlier timing can be an issue and if the remote GW is e.g. on a cellular backhaul it is poss that associated latency esp wrt 3G can be enough to push the system out on timing missing the window. That might explain why even relatively close to it & with reasonable Rossi/sir values you still hit & miss response. Can you contact the owner & enquire? Knowing the gw - type/model/packet forwarder may help also as there is some variability in speed of operation between systems…
In case it helps, @Grillbaer: if you see TTN giving you a DevAddr, then you know it has accepted the Join Request, but if you don’t see a DevAddr, then that might not indicate much. (Like in TTN Console, a Join Request in an application’s Data page indicates such, while the same yellow icon in a gateway’s Traffic page does not give you any clue.) I don’t know what MQTT gives you, but the DevAddr will certainly change in TTN Console, if accepted.
On the other hand: I guess there’s no reason to think it’s not accepted, while being accepted does not guarantee a Join Accept was generated. (Like I assume that if a gateway is exceeding its duty cycle, the Join Request might be accepted, and a new DevAddr might be assigned, but no Join Accept might be generated.)
I’ve seen 2 problems arise - the 1st is if people deploying GW’s dont allow the data to be shown (the tick boxes on GW settings -> privacy page), and after last major overhaul of the map presentation about a year ago the main map shows less data (e.g. no owner shown) with a move to the community page to access the extra info - unfortunately not every GW is in an area that is part of a community…if not in a community the only way to get that info is to reach out to the TTN Core team and request it or if privacy settings dont allow disclosure ask them to reach out to the owner and ask the owner to contact you - not very satisfactory for a ‘community’ effort
I would ask all owners to atleast check all the privacy tick boxes to allow basic data presentation… I do that for all mine, and try to include some basic info about config/location
I saw this exactly one time in the app log, but don’t know from which GW. There was a "error": "Activation DevNonce not valid: already used" in the response JSON. I did not see this in any of the other failed attempts. Is this error generated by the GW or the network, i.e. will it always be visible in the app log, independently of the GW?
I didn’t dive deep enough into that yet, but some hints on timing in the doc made me at least think, that it might improve some timing issues:
… ensure that you call os_runloop_once() “often enough” …
…
… LMIC_setClockError(MAX_CLOCK_ERROR * 20 / 100); …
…
Controlling use of interrupts
#define LMIC_USE_INTERRUPTS
If defined, configures the library to use interrupts for detecting events from the transceiver. If left undefined, the library will poll for events from the transceiver. See Timing for more info.
The current event callbacks or other actions (GPS location received, next message queued) might also take too long. I have to check whether the OLED might be updated when a receive window is due. From other projects I know that this can take up to nearly 100 ms for the SSD1306-I2C-128x64 display. And there is quite a lot of printing in the current code.
Also, I’ve set the clock error to 5/100. Perhaps setting it higher might already solve some problems. Another point for my todo list
I have to re-check that detail, but the join-JSONs on MQTT looked quite complete except for the one case, where there was a nonce error message.
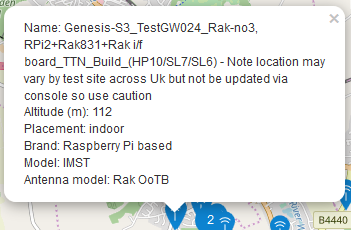
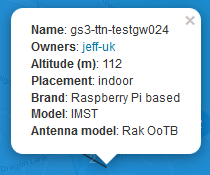
The GW states “Raspberry Pi based” model “IMST”. It’s very likely not 3G connected, since we have quite good internet access here, even in my village (thanks to M-Net), and this GW is located only a few 100 meters from the next Telekom switch station, which (indirectly) provides also my telephone and internet access.
First, I want to check out the possible timing issues on my device side more deeply, but I’m also considering to contact him. His GW log would probably help very much, much less guessing then! Might also be some fun to talk to somebody with this rare hobby so nearby
Thanks again for your almost tutorial-like hints @arjanvanb!
This afternoon, I tried more joins near the other GW, this time with 4x increased setClockError to 20/100 and most display output removed for reduced timing impact. However, I got similar results as before:
The device received 7 out of 12 join accepts, still near 50%.
Each join shows a "dev_addr":"26012xxx" in the MQTT JSON independently of the reception on the device, so should have been accepted.
Sequence: success=1, fail=0: 0-1-1-1-1-1-1-0-0-0-0-1
Part of the sequence in the MQTT log t-beam-ttn-tracker/devices/t-beam-v1-0/events/activations: