Hello,
This is my first post on the TTN forum. I am not a LoRa or TTN expert.
I have searched the forum and found two similar posts here and here. The posts are interesting but neither offer a clear solution I can implement.
Kerlink Support have asked me to get in touch as they believe the problem I am experiencing is with TTN. The node is a Tek766 ultrasonic sensor currently installed on a Water Tank in Rwanda. We have installed many of these devices and they work extremely well. This device in particular was installed a month ago and has worked flawlessly until we recently rebooted the Kerlink Gateway several days ago.

Basically, since the gateway reboot the node keeps giving this message error message every 30 minutes…
Jan 24 11:39:10 Wirnet local1.err lorad[858]: <3> Packet REJECTED, timestamp seems wrong, too much in advance (current=2017916992, packet=2016521172, type=0)
When I convert these timestamps they seem to be in 2033 so something is obviously wrong.
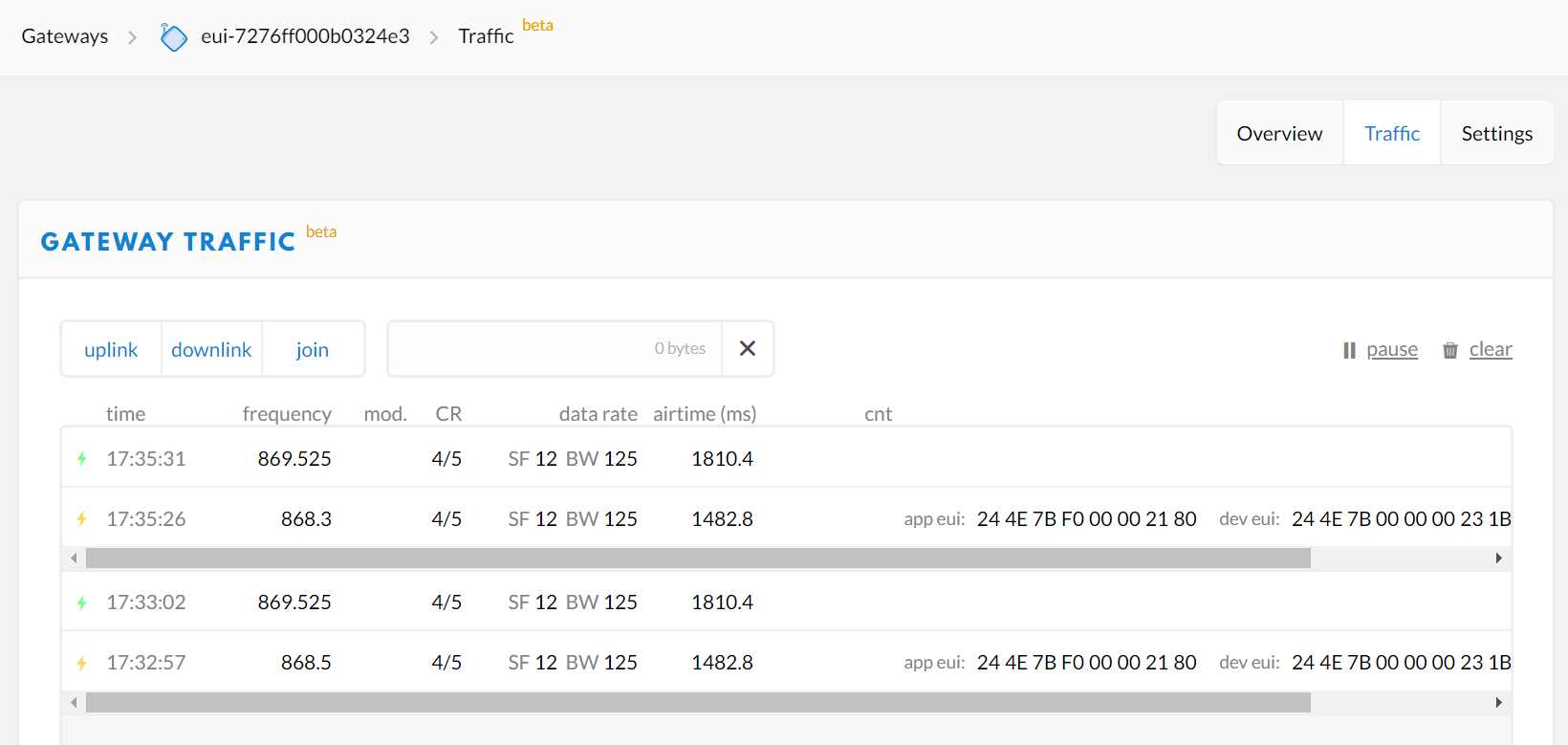
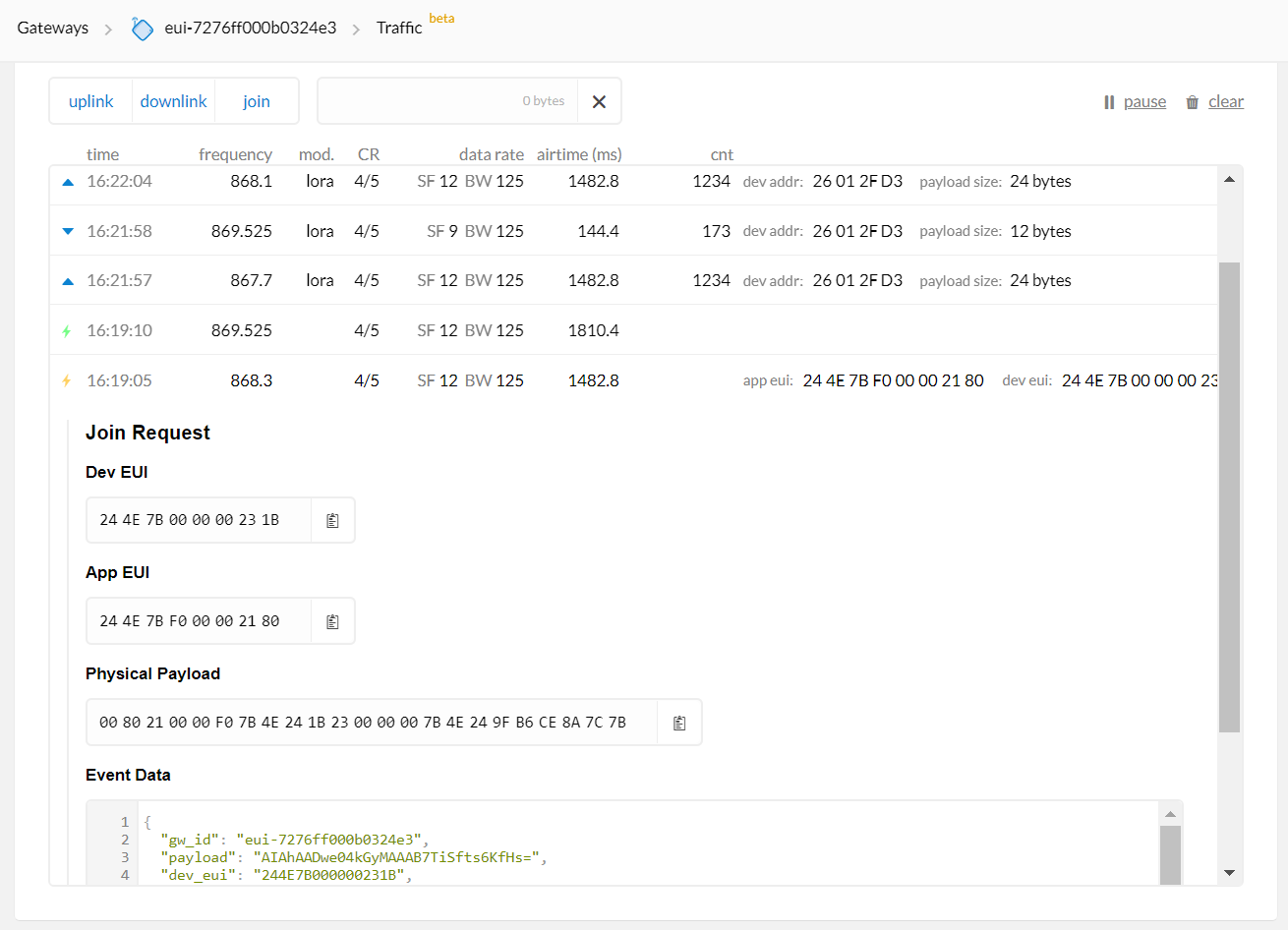
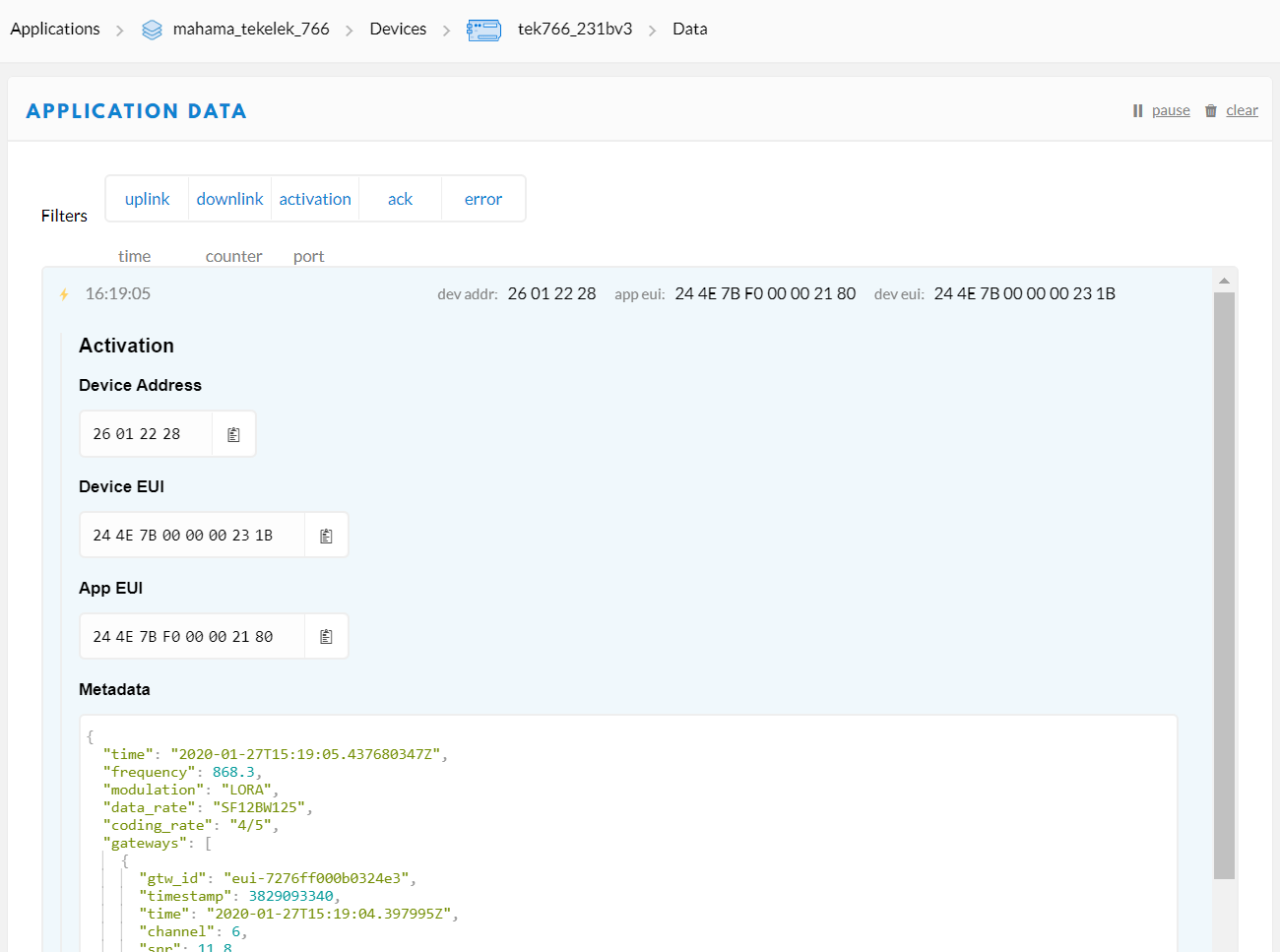
Here is an extract from the Lora.log file showing the JOIN request and JOIN accept.
> Jan 24 11:39:02 Wirnet local1.info lorad[858]: <6> Sent 1 uplink message
> Jan 24 11:39:02 Wirnet local1.info lorafwd[1790]: <6> Received uplink message:
> Jan 24 11:39:02 Wirnet local1.info lorafwd[1790]: <6> | lora uplink (40100049), payload 23 B, channel 868.1 MHz, crc ok, bw 125 kHz, sf 12, cr 4/5
> Jan 24 11:39:02 Wirnet local1.info lorafwd[1790]: <6> | Join Request, JoinEUI 244E7BF000002180, DevEUI 244E7B000000231B, DevNonce 58159
> Jan 24 11:39:02 Wirnet local1.info lorafwd[1790]: <6> | - radio (00000105)
> Jan 24 11:39:02 Wirnet local1.info lorafwd[1790]: <6> | - demodulator counter 2010521172, UTC time 2020-01-24T11:39:02.897931Z, rssi -72.1 dB, snr 7.75< 10 <13.5 dB
> Jan 24 11:39:03 Wirnet local1.info lorafwd[1790]: <6> Uplink message (4105) sent
> Jan 24 11:39:05 Wirnet local1.info lorafwd[1790]: <6> Uplink message (4105) acknowledged in 2102.25 ms
> Jan 24 11:39:07 Wirnet local1.info lorafwd[1790]: <6> Heartbeat (4128) sent
> Jan 24 11:39:08 Wirnet local1.info lorafwd[1790]: <6> Heartbeat (4128) acknowledged in 593.667 ms
> Jan 24 11:39:08 Wirnet local1.info lorafwd[1790]: <6> Uplink message (4106) sent
> Jan 24 11:39:09 Wirnet local1.info lorafwd[1790]: <6> Uplink message (4106) acknowledged in 951.214 ms
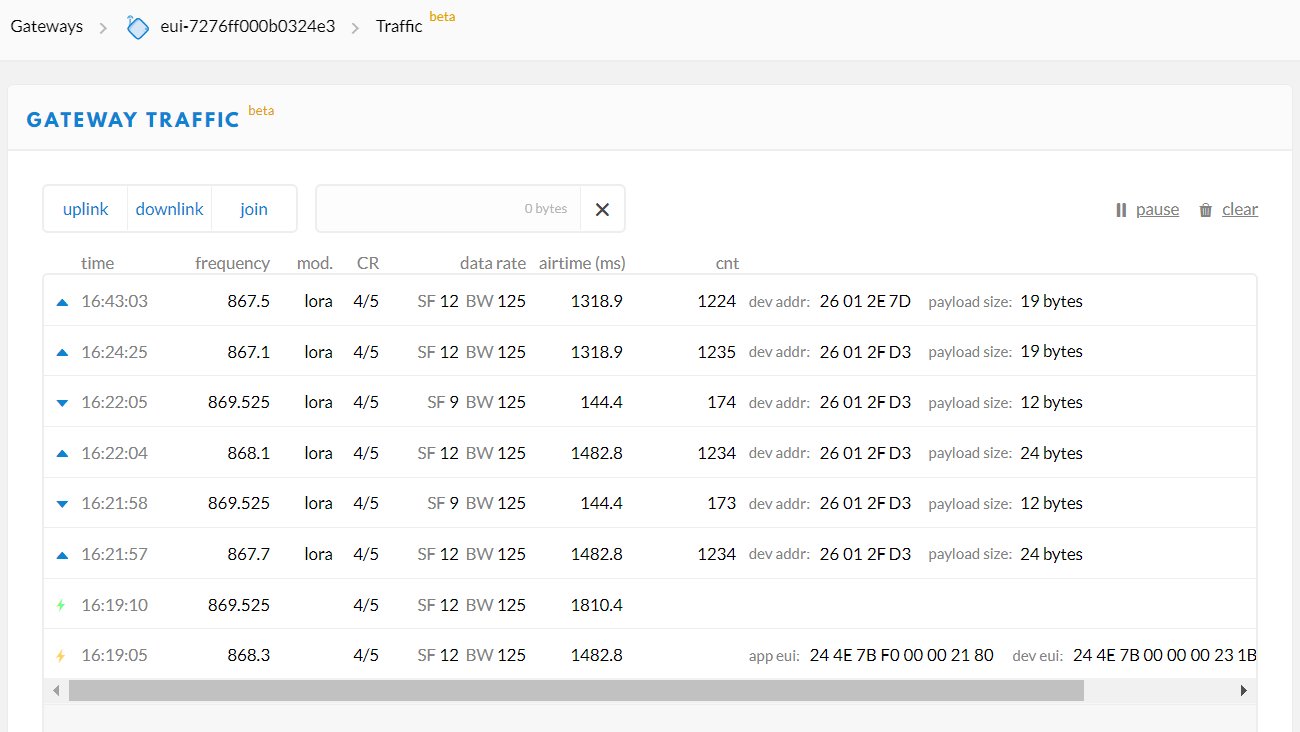
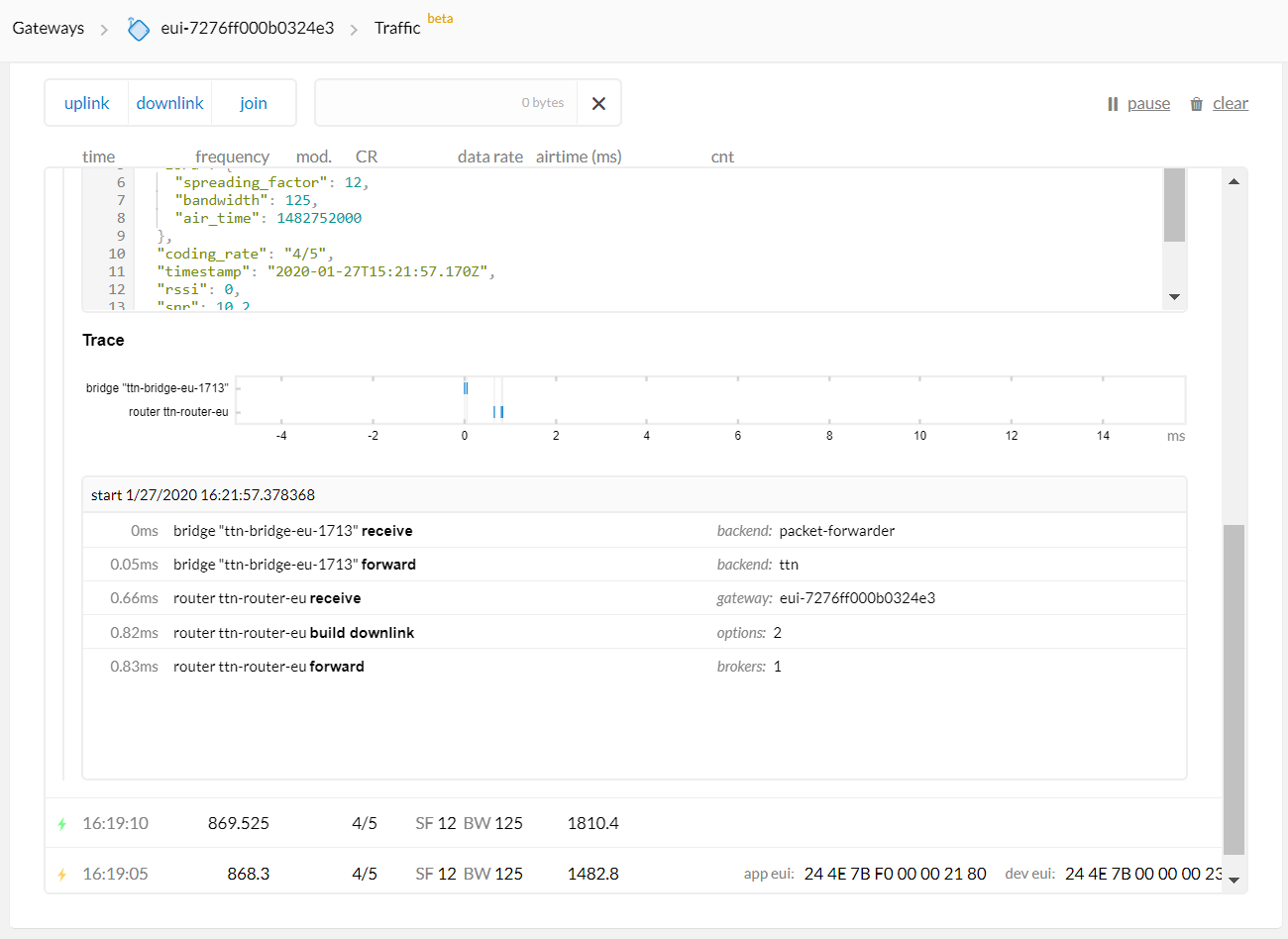
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> Downlink message (2C3E) received
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> Received downlink message:
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> | lora downlink (00002C3E), payload 33 B, required 1, preamble 8 B, header enabled, crc disabled, polarity inverted
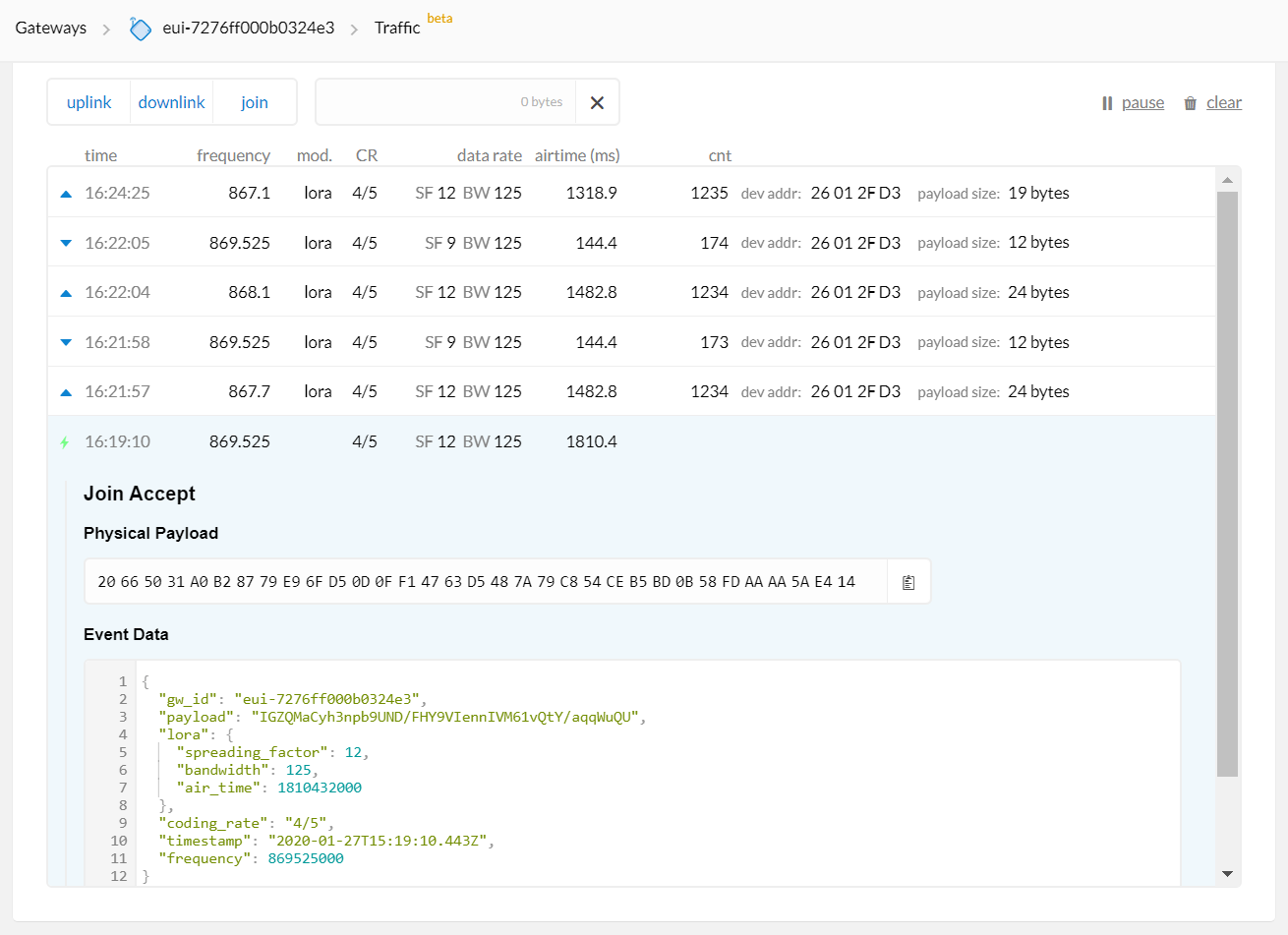
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> | Join Accept
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> | - radio (00000000), channel 869.525 MHz, bw 125 kHz, sf 12, cr 4/5, power 27 dB
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> | - transmission (00000000), priority 1, on counter 2016521172
> Jan 24 11:39:10 Wirnet local1.info lorad[858]: <6> Received downlink message
> Jan 24 11:39:10 Wirnet local1.err lorad[858]: <3> Packet REJECTED, timestamp seems wrong, too much in advance (current=2017916992, packet=2016521172, type=0)
> Jan 24 11:39:10 Wirnet local1.err lorad[858]: <3> Failed to enqueue downlink message
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> Received uplink message: transmission event (00002C3E / 00000000), status "Bad timing"
> Jan 24 11:39:10 Wirnet local1.info lorafwd[1790]: <6> Downlink message (2C3E) acknowledged
> Jan 24 11:39:17 Wirnet local1.info lorafwd[1790]: <6> Heartbeat (4129) sent
> Jan 24 11:39:18 Wirnet local1.info lorafwd[1790]: <6> Heartbeat (4129) acknowledged in 650.129 ms
Here is the message from Kerlink asking me to ask TTN for support…
The error message “Packet REJECTED, timestamp seems wrong, too much in advance”, means the message was sent to late by the LNS (from TTN), so the gateway drop the message because, physicaly , it’s not possible to reach the open frame window of the end-device.
On the Kerlink WMC LNS (lora network server), we have a parameter to balance this delay in the backhaul network (between the server and dthe gateway), so the gateway receive the message earlier from the LNS server, and have the time to treat and send it in time.
Please ask to TTN support to know how to use the same feature.
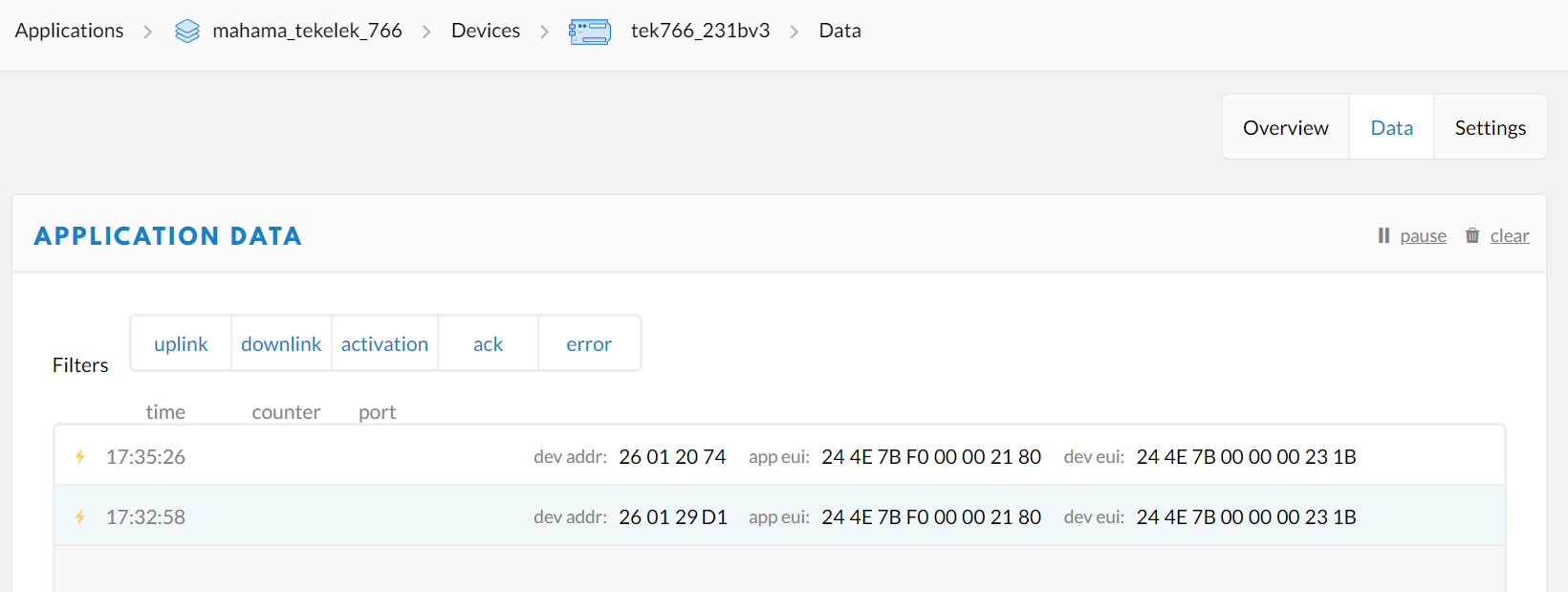
One solution I have tried in order to attempt to solve the problem is to deleted the device, deleted the application, and rename both the device and application with brand new names. However, I seem to end up with the same problem. The JOIN request and JOIN accept work. The device is even visible in TTN Console as green an active ‘several minutes ago’. However the packet timestamps are wrong, the packets are dumped and no data reaches the application.
If anyone can help us understand why there is a problem with these TIMESTAMPS it would be highly appreciated.
Regards