Yes, here is some traffic on the same Gateway for two other nodes.
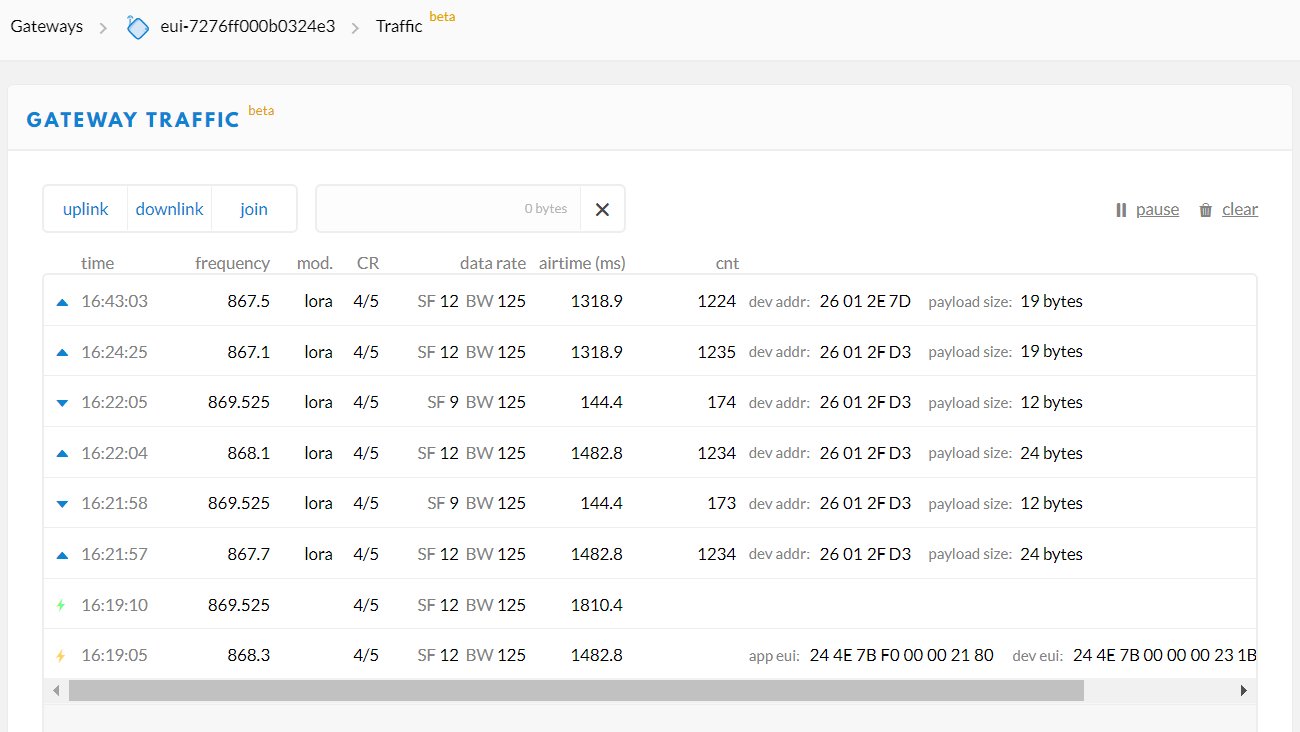
The message interaction appears to be very quick…
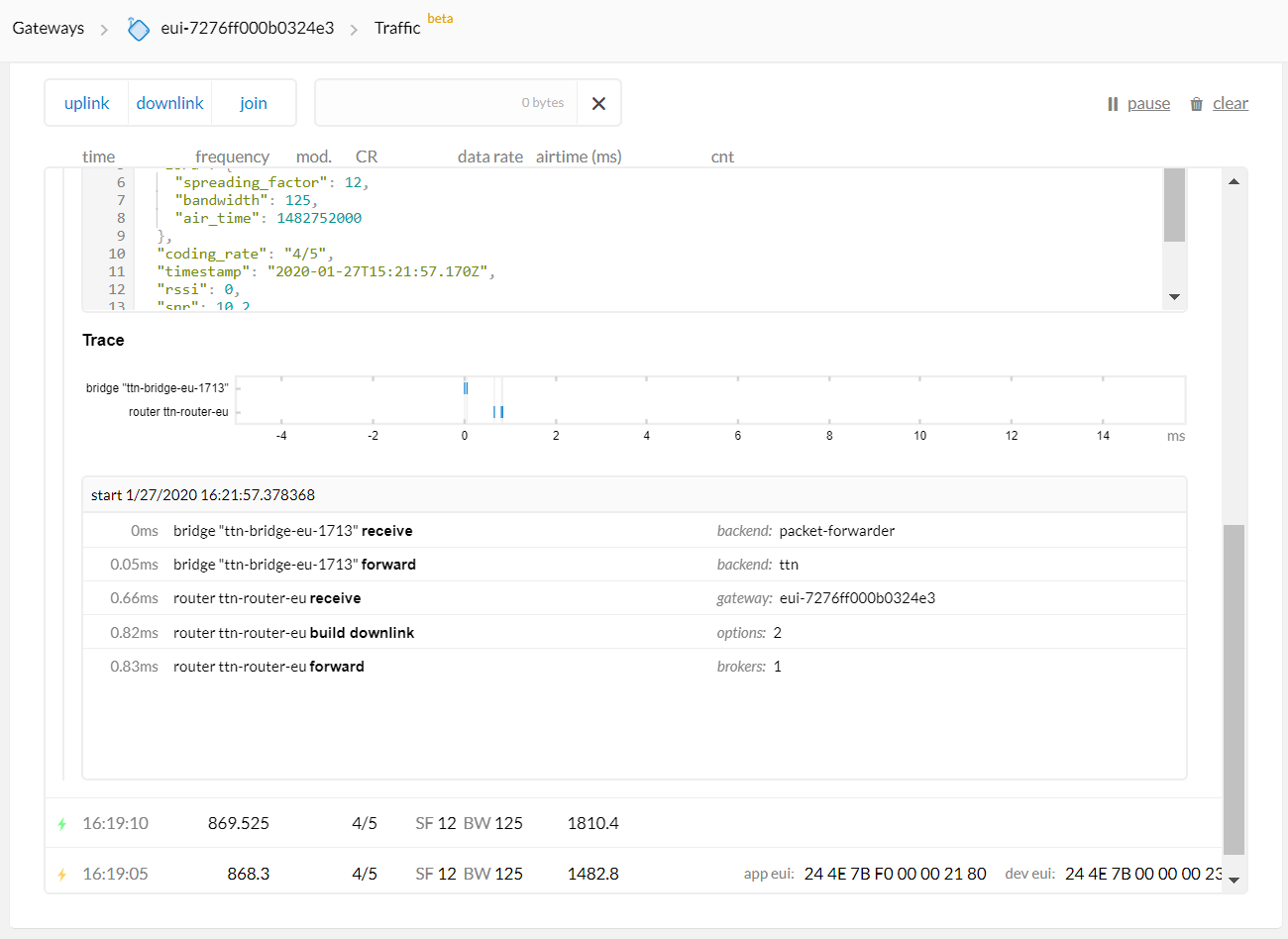
These other nodes seem to be fine - is this an indication the problem is not with the Gateway?
Thanks again for helping us with this - I am aware we are taking up a lot of your precious time, it is appreciated.