EDIT/TLDR: The Milesight UG63 v2 gateway has problems with syncing time and can’t schedule down packets correctly. It also seems to not even allow firmware updates. I’m returning it.
I’m new to LoRaWAN and got some hardware set up, but having trouble joining the node to my app after a whole day of debugging/searching. I’m following Wio-E5 Development Kit | Seeed Studio Wiki
I’ve set up a public gateway and configured it on TTN. I’m in Australia.
I’m talking to the E5 dev board via AT commands. I’ve created a device in a TTN application, manually configured it by entering the DEV and JOIN (APP) EUI’s from the device. I generated an app key on the TTN console for that device and set it on the device via AT+KEY=APPKEY,“key goes here”.
Also set up the device in the TTN console to be AU915 FSB 2, LoRaWAN v1.0.2, RP v1.0.2B.
I also ran AT+DR=AU915 and AT+CH=NUM,8-15. I’m not sure of the channel numbers based on all the searching I’ve done, it seems that channels 8-15 is FSB 2? I did try 0-7 without any up messages coming into TTN console at all.
I’ve also run AT+MODE=LWOTAA.
When I try join using AT+JOIN, it says this:
AT+JOIN
+INFO: Input timeout
+JOIN: Start
+JOIN: NORMAL
+JOIN: Join failed
+JOIN: Done
However I do see messages in the GW and in TTN console GW logs and App logs going “up”. TTN app replies and sends “Forward join-accept message” to the GW (in the TTN GW activity) “Send downlink message Tx Power 30 Data rate SF12BW500”.
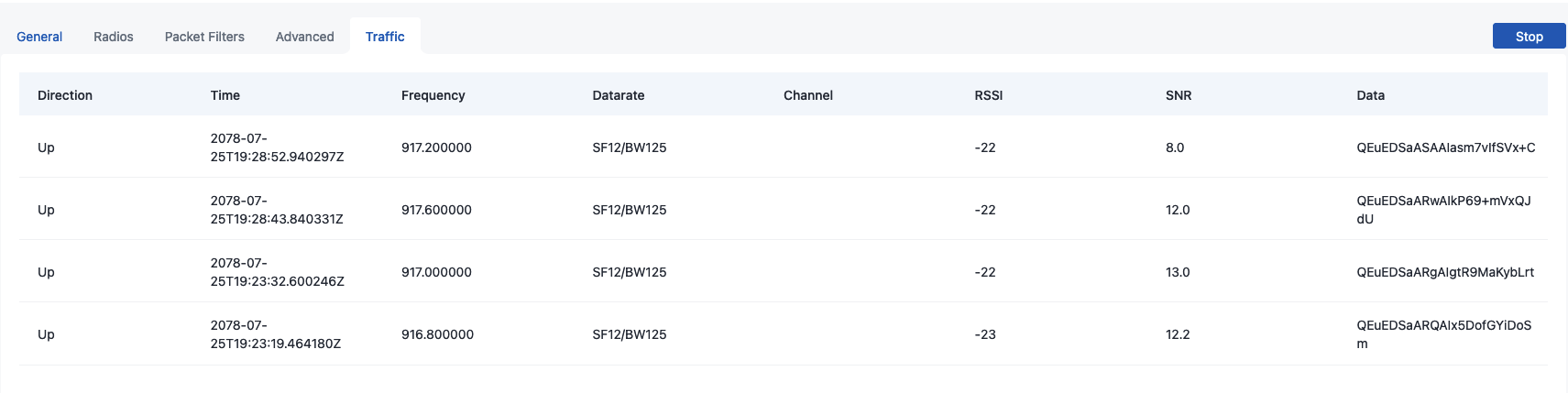
The GW itself has a simple radio traffic log that shows packets. So far I’ve only seen “up” packets, including mine and some rare random packets. There’s not much activity in my area so it’s easy to keep track.
I have not seen any “down” messages on the GW itself so I suspect, for some reason, TTN and my GW has a communication problem. (Or maybe the GW doesn’t log down packets)
My GW is a UG63v2 and I’ve left the radio settings as default, which was preconfigured with AU915. I also set up the GW Basics Station via CUPS which I understand sets up LNS for me (however I see no LNS URI, which might be a problem).
Can I get some suggestions to debug this further? Cheers!