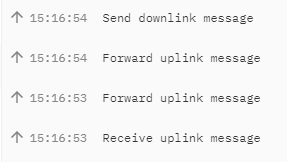
In the Console Live data view of my V3 gateway I see that each received uplink message is forwarded twice. My gateway is ‘LoRa Basics Station’ based.
Comparing the Event details of both forward events does not give much information.
Why is each received uplink message forwarded twice?
The ‘Send downlink message’ event shows an up-arrow like is shown for uplink messages.
I would expect to see a down-arrow here but is not the case.
Is this a bug in the console?
It could be peered traffic from a private TTI deployment registered node that is picked up by a TTN GW then routed through PacketBroker to TTI hence the forwarding… the GW is transparent and just passing packet through and only TTN back end will know for sure if it is a TTN or TTI node so to avoid latency/delay scheme is likely auto forward to PB, whilst the TTN decides if it is indeed for one of its registered devices, then either PB can drop if not targeted to a TTI instance or the back end TTI instance can ignore if not for it?!
It is traffic from my own V3 device arriving on my own V3 gateway that gets forwarded twice to the next link in the process. So second forward is to the packet broker (not my V3 application) but who/what is going to use/need it?
There is no brokering from TTN V3 to V2.
Is there brokering from TTN V3 to private V3 instances but not vice versa?
Exactly - system cant wait for a decision of “is this Jeff’s node talking through Jeff’s GW to Jeff’s application in TTN V3 Application server?” before deciding nope it’s for a TTI private instance that has peering set up - as that would introduce too much delay/latency - so I suspect defaut is push to PB at same time as push to TTN V3 App server instance… hence double forward…
In all The Things Stack (v3) deployments managed by The Things Industries, all traffic is forwarded to Packet Broker. The routing policies in Packet Broker then determine if and where that traffic gets routed.
We call this peering. Packet Broker is configured with routing policies that send uplink messages from the “forwarding” cluster to the “home” cluster:
So when the ttn-nam1 cluster sends an uplink for DevAddr 26091234 to Packet Broker, that gets routed to tti-ch-nam1, and when the tti-ch-au1 cluster sends an uplink for DevAddr 260D1234 to Packet Broker, that gets routed to ttn-au1.
When the ttn-eu1 cluster sends an uplink for DevAddr 260B1234 to Packet Broker, it will not get routed to any other network, because it doesn’t match any routing policy.
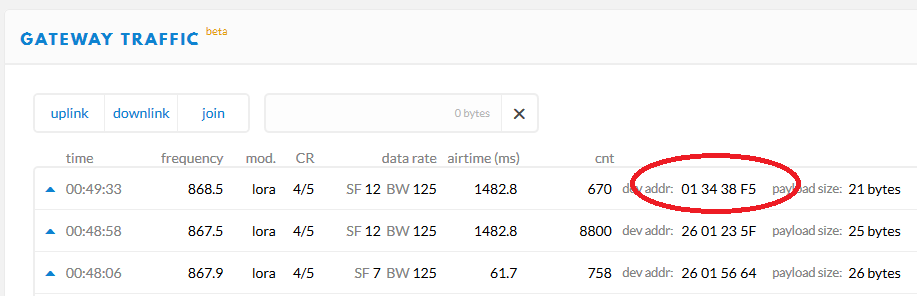
I see a reasonable number of packets arriving on my gateways with NetID = 0x00 rather than 0x13. Reading more detail on Packet Broker I can see the Network Server uses this to determine if it will process the packet or hand it off to Packet Broker to deal with.
The application is currently working on V2 with all packets being processed and forwarded to the Application Server.
Wondering if you clarify how V3 will handle the packets with NetID = 0x00 as the Australian Community may need to advise some people they may need to reprogram their nodes when they migrate.
I guess my specific question, does the V3 network server, in addition to NetID=0x13, also accept NetID=0x00 and send the rest to Packet Broker?
Hi, this is kind of related to my question here from a few minutes ago.
How is the routing of NetId 00/01 handeld? I would like to not forward them at all, but keep them local only it keeps private experimental networks private and saves bandwidth.
IIRC 00/01 nodes are defined as experimetal and universal (can be used by anyone vs tied to one user or network/netID) vs something local and unique to you. I believe TTN has historically not only allowed the normal 26/27 nodes to be handled but also allowed for experimental nodes - to help encourage experiments and innovation, with others being dropped in the back end (the PB ofcourse now potentially allowing for peering with those netID’s where correctly configured and reciprocally balanced). I hope that continues in V3 ( I haven’t tested yet), and would note that the scheme you outlined elsewhere, where you filter 00/01 locally and do not pass on to TTN, would be disruptive to other users in range and their expectations and needs?!
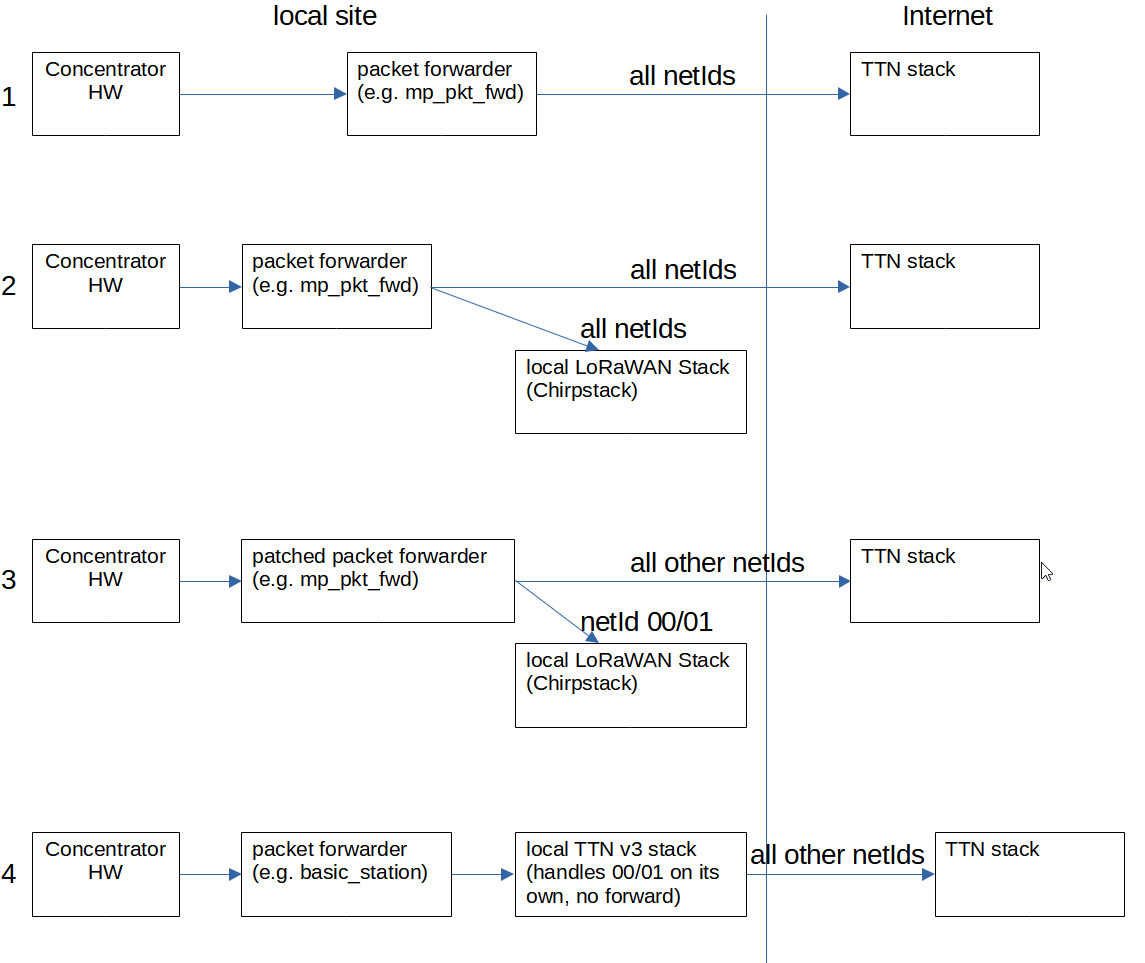
Hi @Jeff-UK, interesting point. I do not think that though. From my understanding this would mean, that the network server of TTN would hand out device addresse reflecting a netId of 00/01. So devAddrs starting with 00/01 something instead of 26. I created an explaining picture. I see 4 scenarios. Scenario 1 is very common for people who have gateway hw and do not want to take care of the stack. They use whatever packet forwarder to forward everything they have to the TTN stack in the internet. Scenario 2 is for people who also have a local LoRaWAN stack installed. All packets are seen by both stacks now while the local one handles netIds 00/01 it will throw away anything it feels not responsible for. The TTN stack will receive also all packets and throws those away it feels not responsible for. I assume it will throw away 00/01 (and also think packet broker as well). I guess this is the scenario from @TonySmith. Scenario 3 is what I am running, where only netIds 00/01 are forwarded to the local LoRaWAN stack and filtered out from the upstream to the TTN stack. I did not wish data for event driven sensors to be transmitted into the internet (e.g. a doorbell or a PIR sensor). And finally scenario 4 is what I would like to have. A local TTN v3 stack does the filtering while at the same time reporting that it is able to transmitt downlinks to nodes if they do not conflict with the local 00/01 network.
No, I believe the scenario assumes user sets a device up using ABP, or doesnt register at all as in example use case below… choosing a 00/001 address for their device to declare it ‘experimental’. TTN then doesnt simply drop it, as it would with one from another official but unsupported netID
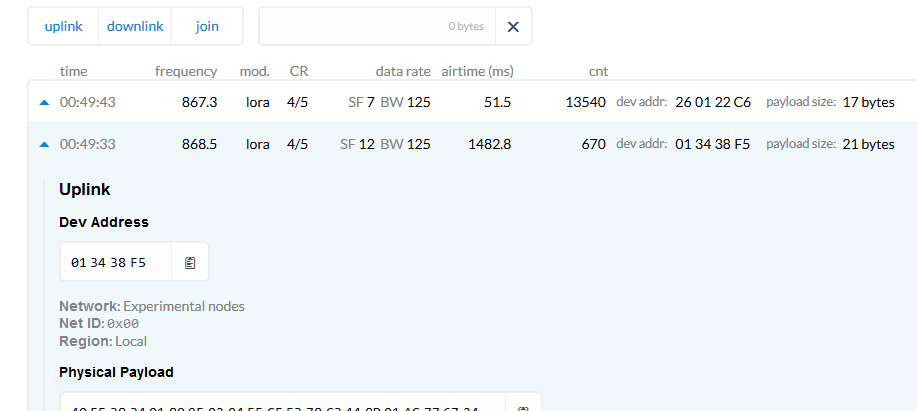
e.g. this one just captured by one of my GW’s
I, and I know many others, use experimental nodes when developing or when e.g. conducting coverage surveys. You can quickly fire up a node and move it around, without having to go to the trouble of setting up an application on TTN, adding a device etc and burdening the back end/storage etc. as all you want is live - albeit transient data to indicate coverage. By wandering around the area of interest with an iPad for example, tethered for internet connection logged in and showing the target gw in the console you can see the node data coming in and confirming coverage as node moves. If I were to try and map your GW’s coverage if they filter out and dont pass on the 00/01 messages I would then get false impression of no TTN coverage
Ah, interesting. So they only need and use the metadata.
Mhm, is that something that can and must or should be supported by “TTN comaptible” gateways? And then of course does this change as well with packet broker and TTN stack v3?
Remember in LoRaWAN GW’s are supposed to have no direct role in handling messages, their purpose in a ‘pure’ network, is simply to capture valid LoRaWAN messages and transparently forward them, unadulterated, to the NS which has the ‘handling’ responsibility.
You might assume that if a gw is to be connected/registered to TTN then it should, as a minimum, support the services supported and offered by TTN, for that reason we do not want single or dual channel packet forwarders connected as they do not support the service offered, and being non compliant to LoRaWAN only support limited channel capability and overall capacity etc. - and indeed are potentially disruptive. On one view the same might therefore be said of a GW that fails to handle messages suited to the TTN operation - including allowing 00/01 device messages through As noted earlier I havent yet tested with V3 personally but sincerely hope this hasn’t been dropped (will be mapping 1st V3 GW next week so guess I will soon find out!)
Not sure how best to define ‘TTN compatible’ but on 1st principles I would refer you to the TTN Manifesto, which you are effectively adopting when choosing to connect to and use the facilities and services of TTN. Specifically I would point you to bullets 4 & 5 (Handiling messages on basis of net neutrality and annonymously) So if filtering that is not neutral, and I guess if forcing a user to register a device (to get a 26 vs 00/01 dev addr) then potentially that is no longer annon
Yes, very good. An important reminder.
I wonder how this then works for scenario 4. The ns is local and might have the handed out the same 00/01 devAddr as your mentioned APB devices. Does it forward then only those which can not be decrypted correctly? That would be perfect then for me as my local devices still only stay local.
DevAddrs are not unique…there used be only 4K IIRC though I think this is now increase to 8K, TTN uses combination of DevAddr & AppEui to uniquely ident & fingerprint I believe. Sure someone more knowledgable will comment/confirm/correct as needed.
Note: all this is w a y o f f topic for thread title above and all need moving across to the other thread discussing filtering. Please don’t extend conversation here until we have chance to move… I don’t have time right now and difficult to shift all on iPad vs when back at PC
We have configured all The Things Network clusters such that all traffic that is received by gateways connected to a certain v3 cluster will be offered to the Network Server of that same cluster.
Packet Broker does not route NetID 0 (because nobody owns that NetID), so if your gateway is connected to one (v2 or v3) cluster, you will not receive uplinks for DevAddrs 00000000/6 in another cluster.