Hy there,
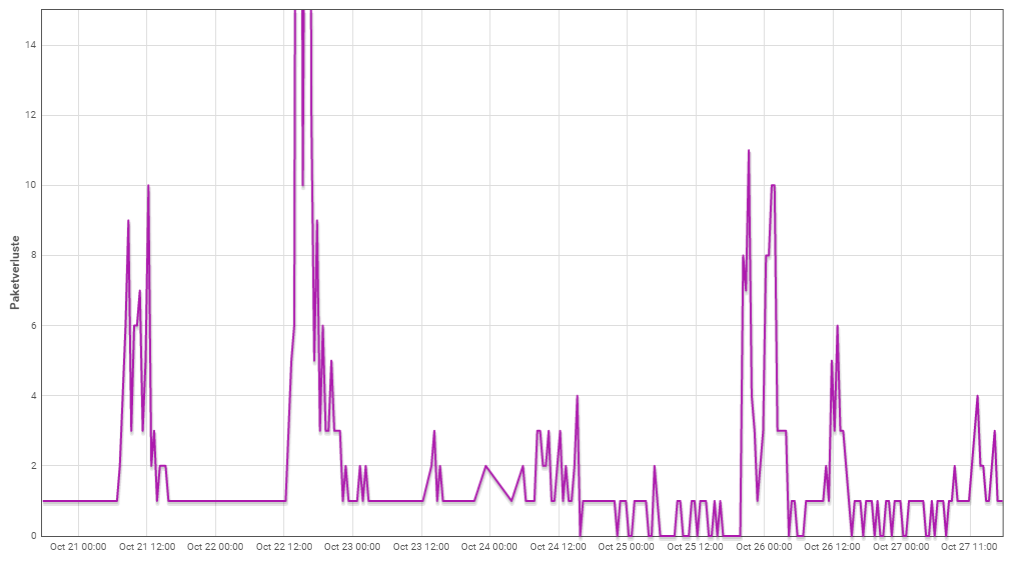
we are logging data losses for some test nodes. Over the last days we had increased loss rates. The following log was written within node-red, it gives the node packet counter, the time since last reception and a time stamp:
{"arduino_test":10377,"arduino_test_delta":2463.921,"timestamp":"2019-10-22 14:13:19","arduino_test_lost":40}
{"arduino_test":10416,"arduino_test_delta":2336.506,"timestamp":"2019-10-22 14:52:16","arduino_test_lost":38}
{"arduino_test":10427,"arduino_test_delta":664.953,"timestamp":"2019-10-22 15:03:20","arduino_test_lost":10}
{"arduino_test":10428,"arduino_test_delta":57.415,"timestamp":"2019-10-22 15:04:18"}
{"arduino_test":10454,"arduino_test_delta":1557.818,"timestamp":"2019-10-22 15:30:16","arduino_test_lost":25}
{"arduino_test":10496,"arduino_test_delta":2519.84,"timestamp":"2019-10-22 16:12:16","arduino_test_lost":41}
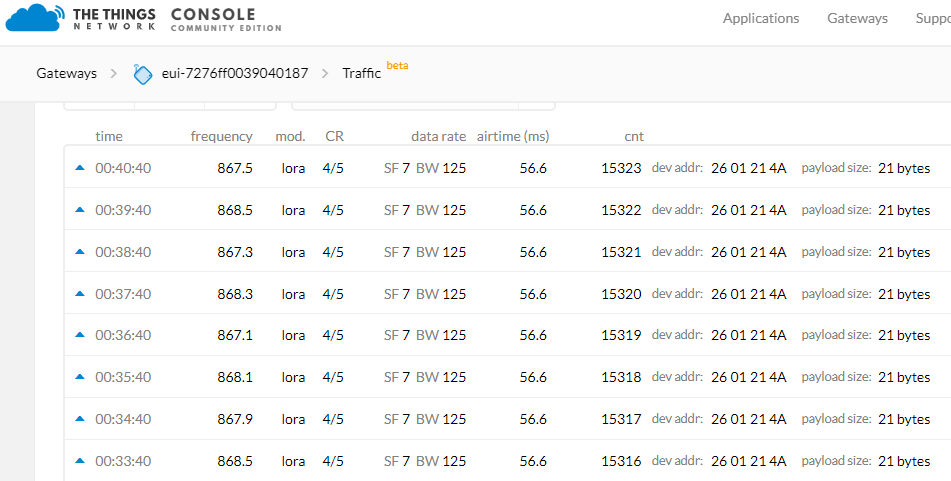
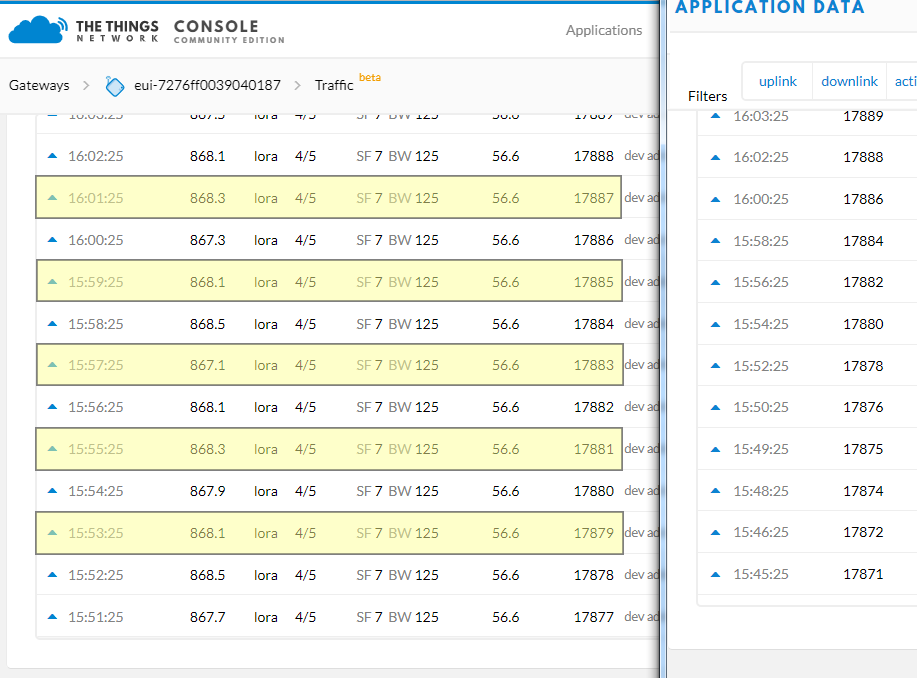
Checking the gateway logs I found, that during the “downtime” lot´s of data have been sent:
Oct 22 15:48:45 klk-wifc-040187 local1.info lorafwd[3036]: <6> Uplink message (EF17) sent
Oct 22 15:48:45 klk-wifc-040187 local1.info lorafwd[3036]: <6> Uplink message (EF17) acknowledged in 39.104 ms
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> Received uplink message:
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> | lora uplink (7B305FE4), payload 27 B, channel 868.5 MHz, crc ok, bw 125 kHz, sf 7, cr 4/5
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> | Unconfirmed Data Up, DevAddr 27008866, FCtrl [ADR], FCnt 4895, FPort 1
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> | - radio (00000107)
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> | - demodulator counter 2126864916, UTC time 2019-10-22T13:48:48.059476Z, rssi -62.2 dB, snr 4< 7 <9.75 dB
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> Uplink message (EF18) sent
Oct 22 15:48:48 klk-wifc-040187 local1.info lorafwd[3036]: <6> Uplink message (EF18) acknowledged in 37.5419 ms
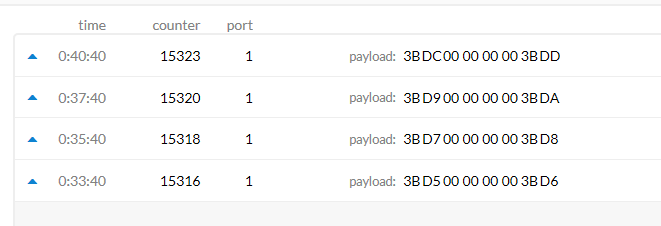
So, it lookis like data have been transmitted, but do not reflect in the backend. We are usint ttn-contrib-nod-red to receive data in node-red.
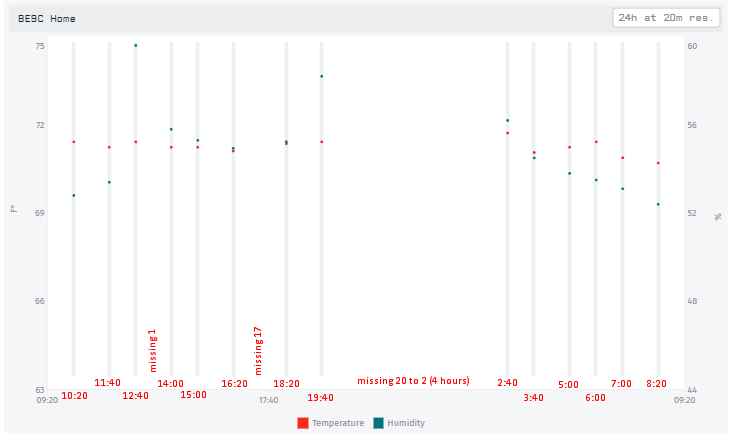
I know there is a status page, but this gives us only current status. Is there any status history to see, if data losses are caused by downtime or maintenance?
 included) TTN is a springboard to TTI.
included) TTN is a springboard to TTI.