Hi everyone,
I am using a Multitech Conduit AEP with The Things Stack with some OTAA and ABP devices.
There is one in particular that needs the Frame Counter Checks be disabled in order to works properly.
Using TTN, this option was available when registering it. With Stack there is only the option Reset Frame Counters but with or without it checked, my device does not works properly.
I’ve tried different LoRa MAC versions, but none make it works.
Is there any additional configuration I have to do so I can disable frame counter checks??
It does not seem like checking “Frame Counter Resets” works in the current TTNv3 stack. I filed a bug report for it:
In general the strict frame counter checking of V3 is causing many issues for many people. Just check all the comments on Slack the past couple of days. I know that TTI wants to be 100% LoRaWAN compatible, and therefore doesn’t want to ignore frame counters. But there are some instances where devices will fall off the network.
Some points why I believe we need the feature “disable frame counter checks”:
Most old ABP devices, including the Things Uno, and LMiC, will reset their frame counters when the device restarts. Embedded devices are very often designed to be stateless. They run Firmware. Firmware doesn’t change over time. It is stateless. That’s why it’s called Firmware and not software. Whenever something out of the ordinary happens, the device will restart, mostly via a Watchdog Timer Reset. After a reset the assumption needs to be that you have a clean slate to work with. Storing frame counters goes against this. Also reading and writing flash memory can cause many issues, and one needs to be able to recover even if reading the previous frame counters from flash memory failed.
Balloon experiments: Messages are received by many gateways. Some gateways take much longer to forward messages than others. In the past we had to disable frame counter checks to be able to receive all messages from all gateways.
The current behaviour that I see is that “Frame Counter Resets” does not work on V3. This is likely a bug. If this bug is fixed, I believe the most issues with ABP devices (where frame counters reset) will be solved.
While not really meaning to disagree with you, I’d point out that this view is in direct opposition to the design philosophy of LoRaWan.
For better or quite possibly worse, LoRaWan is just not designed to work with nodes which do not maintain state in terms of frame counters, or past utilized join nonces.
Balloon experiments: Messages are received by many gateways. Some gateways take much longer to forward messages than others. In the past we had to disable frame counter checks to be able to receive all messages from all gateways.
It would be interesting to know if the increased RX1 delay also includes an increased de-duplication window.
But as a further example, LoRaWan doesn’t really work with the idea of offline gateway packet archives to be decoded later (and thus potentially out-of-order) either.
For the recent versions of the standard you are right. For the 1.0.1 version of the stack there weren’t any issues with stateless devices. The recent changes mandating increasing nonces and the like make the stack more robust but also complicate node design. Not an issue for experienced embedded engineers (apart from the potential increased bom costs) but challenging for the average amateur and impossible to implement on some of the hardware used for TTN projects. (Yes, I am familiar with your opinion on that hardware)
I don’t believe that’s actually the case. Do you have a link to a 1.01 version of the specifcation? It no longer seems to be available. Anyway, TTN implemented 1.02 and that mandates that uplinks with re-used frame count or join nonce be ignored.
What has changed a little is the recommendation with regard to “guessing” to “fish” for an un-used valued - but actual re-used nonces weren’t accepted before either.
and impossible to implement on some of the hardware used for TTN projects.
What hardware would that be? The Atmega series includes EEPROM, most of the ARM based devices have enough flash for a walking type emulation, and the ESP’s definitely do.
The key though is a sort of strategy where you write a bit for each value or block of values used. If dealing with raw frame count which changes frequently, it’s probably worth using say one bit for every 16 values. Then on startup you assumptively mark the remainder of the current group used and skip forward to the next clean value of 16.
Tricky, yes… impossible, not at all. But few of the stacks seem to bother. LoRaWan is indeed an extremely complex thing to implement with actual spec accordance - if you follow the efforts to validate LMiC it’s run into all sorts of dark corners that the spec makes possible, even if typical operation will hardly ever visit.
The one place it becomes somewhat less do-able is on an MCU where the internal flash has ECC, and thus it isn’t possible to come back and write additional bits in the same word away from the erased value. But a common example where that is true - the STM32L0 series - also has true EEPROM alongside flash.
When people speak of things like watchdog resets, etc. It’s also worth keeping in mind that resetting an MCU does not actually erase RAM; C startup code does, but that’s configurable most easily by shrinking the linker map. Many parts also have backup registers. Some state written to RAM or registered with a good checksum for validation can thus typically be resumed; something that may work well in conjunction with a “large block” non-volatile tally - eg, mark out ranges of as many as 256 frame counts, with most restarts other than those from battery failure finding the RAM value and checksum valid and so not actually having to skip forward.
We treat FCnt resets as first-class feature, but, unfortunately, it was broken in recent optimization changes. I’m currently working on a fix and it will be available ASAP
By using a good random generator and joining on reset it was the case for all practical purposes. Not for nodes rebooting and rejoining every uplink, but for nodes rejoining every two months or so didn’t encounter issues.
And that is where your experience sets you apart from the average TTN user. You know about issues that might occur when writing multibyte values to eeprom because you are an experienced embedded engineer. You are part of a minority on the forum. Or do you expect people struggling to get LMIC pin settings right to be able to implement this correctly? I don’t. And in the past they didn’t have to.
That’s noticeable when looking at the Semtech stacks. I am kind of surprised that code seems to pass the validation.
That’s right. However if a watchdog reset is required to recover a device from failure its better not to trust variables to have sane data.
Relatively few people do a port of a LoRaWan stack to a brand new hardware platform. So it’s rather that people authoring such ports should really put some effort into handling this (if they actually intend to implement LoRaWan), rather than handwaving it away.
That doesn’t actually authorize nonce re-use, it merely proposed random fishing to find an un-used one.
The problem there is that many bad hardware ports also end up with not very random numbers. And counting from an initial (less than) random guess is a bad strategy, because it takes longer and longer to reach an unused value each time…
However if a watchdog reset is required to recover a device from failure its better not to trust variables to have sane data.
I wasn’t proposing trusting variables on their own, but rather in the context of a checksum. One could go a step further and compare them to an eeprom/flash dirty log. Eg, if the RAM value is within the range of usage recorded by in NVM, and if its checksum is valid, then run from there (worst case, uplink rejected until next block transition), otherwise, skip forward a block of 256 or whatever values.
I don´t think so. This is typically a problem for ABP Devices, Your device uses OTAA where the counter resets after a new join - which is fine.
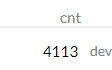
If the Counter of an OTAA device is 4113 right after joining something seems to be wrong. Are You sure this Value is correct?
The “last seen 32 seconds ago” indicates the Application is getting the messages.
I am sure it is the same device in the application and the gateway - The DevEUI is the same.
If you look at the messages on the App it tells you it joined, but it does not pass the data to the mqtt, also you don’t see the decoded data in the APP “Live Data”
Re “If you look at the messages on the App it tells you it joined, but it does not pass the data to the mqtt, also you don’t see the decoded data in the APP “Live Data””
I’m having the same problem with an OTAA device, cant get the count to reset so I get a DevNOnce already used message
You can not have the same issue with OTAA. DevNonces are not the same as the counters used for uplink. DevNonces can not be reset. If using LoRaWAN 1.0.3 and below you need to make sure you use a true random generator, not a pseudo random that generates the same sequence of numbers after each reset. For LoRaWAN 1.0.4 and up your DevNonces need to increase so you should store the last used number.
To get a clean sheet with regards to DevNonces you need to delete the device from the application and recreate it.