Hi!
I am using TTN Indoor Gateways with RN2483 nodes. After registering a node at TTN with setting deveui, appeui and appkey and saving these numbers and other initializations in RN2483 EEPROM with mac save command I can start transmissions (unconfirmed).
That worked very well the last month but until 2 weeks ago all my Gateways were suddenly offline for a few hours. After that, all my nodes could no longer send anything.
But for this, I check in my code after each transmission the response and if the response is not mac_tx_ok then a flag would be set and in my case, the watchdog timer overflows and triggers a reset.
But that didn’t work in this case!
Here is my program flow after starting the software
RN2483 Reset
(Response is RN2483 1.0.5 Oct 31 2018 15:06:52)
join OTAA
If the join process was successful, go to step 3 otherwise repeat it in 10 minutes
RN2483 sleep
RN2483 wake-up from sleep mode
Send data
RN2483 sleep
RN2483 wake-up from sleep mode
Send data
…
What is a good way for
How to check if something is wrong with communication between node and gateway
What to do if something is wrong - make a reset wit a new join process?
I think you first need to determine why things are failing now.
When using unconfirmed uplinks, and assuming the node does not try to exceed the built-in legal maximum duty cycle, the RN2483 will always return mac_tx_ok, without it knowing if its transmission was received by any gateway. (Also, if it is exceeding the limits, then you should not restart the device on getting no_free_ch.)
As the problems started when the gateways were offline for just a few hours, I’d guess your nodes are transmitting quite a lot (or: too often?) and maybe the gap between the counter of the last received uplink and the current ones has exceeded the maximum gap of 16,384 messages?
If not, then I’d assume that the nodes use ADR. With ADR enabled, if a node does not get any downlink from TTN for some extended period then it will automatically request one explicitly. And if it does not receive that one either, then it will decrease its data rate, and at some point might even fall back to SF12. Again, I’d guess your nodes are transmitting quite a lot (or: too often?), making ADR notice the missing downlinks quite soon. Maybe you could try to detect the uplink’s low data rate. But there’s no reason why the TTIG would not handle low data rate uplinks, so triggering a re-join might not even solve this.
So: how many message were missed, what’s the current SF, why does the TTIG not receive it, does the TTIG receive any other traffic, are you sure the devices do not transmit?
The mac_tx_ok response from the RN modules when using unconfirmed transmits simply states the module was able to transmit the data. It does not in any way check the data was received by any receiver.
To check if data is being received you need to use confirmed transmissions. However, each confirmation packet counts towards the 10 downlinks you are allowed to use each day. So you can only use 10 confirmed uplinks (and no additional downlinks) a day.
You could divide the maximum number of uplinks for your device by ten and change every (uplinks/10) uplink to be a confirmed uplink. That could make you rejoin too soon as missing a single acknowledgement is to be expected in busy regions, so the node could rejoin after missing 3/4/an entire days worth of acknowledgements. Keep in mind each node has a limited rejoin capacity. The limit is 64K, but as there is a ‘random’ number involved you will experience random number collisions after just a few hundred rejoins. A join attempt with a previously used random value will be ignored by the back-end and required a new join attempt to be made.
What intrigues me is the issue of the nodes not resuming operation after the gateway got back on-line. How often is a node sending data?
Also, you’ll need to consider what a re-join actually fixes. On top of my head, I’d say that only the reset of the frame counters matters. (Getting new session secrets does not help by itself; the old ones should really be just fine.)
Of course, a device restart might also fix a node’s hardware/software issues, but that does not necessarily need a re-join as well.
No. It means at least one in every 16384 messages must be received and forwarded to the backend. If the last message processed by the backend differs too much from the counter in new messages the new message will be ignored.
Short explanation:
If TTN receives an uplink packet with counter 100, it must receive another uplink before the counter reaches 16485 (last counter value + 16384 + 1). Packets with counter values > 16484 will be ignored by TTN in line with requirements in LoRaWAN standard.
BTW: Perhaps you could take a look at the LoRaWAN standard document? That is where we get our information as well…
Thank you for information and for your hints!
In this case i want to check the status byte from RN2483 every hour. Bit number 4 shows the Join status (‘0’ – network not joined, ‘1’ – network joined).
But here i got another strange problem - if i implement this in my code, suddenly on microcontroller side the RX-Interrupt will not be triggered anymore.
And this has to do (so i am sure) with the RN2483 sleep mode, because it works when the module is not in sleep mode.
But for this problem i posted a separate threat here:
If i understood right, when i save with command mac save after every unconfirmed or confirmed transmission i don`t need a rejoin OTAA.
But what if i have to reset my software and in this case i reset the RN2483A modul?
If i do that, after restart i check the status and it shows 00 00 00 00 - that means not joined.
Do I write you do not need to rejoin in that message?
After a reset of the RN2483 module you will need to rejoin. However if you saved everything after the last transmit, you can use ABP join which basically initialized the LoRaWAN stack within the module without transmitting/receiving.
If the code on the main controller does not reset the RN module when the main controller is reset you do not need to rejoin. However in a lot of cases the main controller will be reset by removing and reapplying the power of the node and that will reset the RN module as well.
OK I have a question to this. If I store the session secrets. Disconnect the power f.e. Some days from my module and restore the secrets. Can I send when new uplink without rejoin?
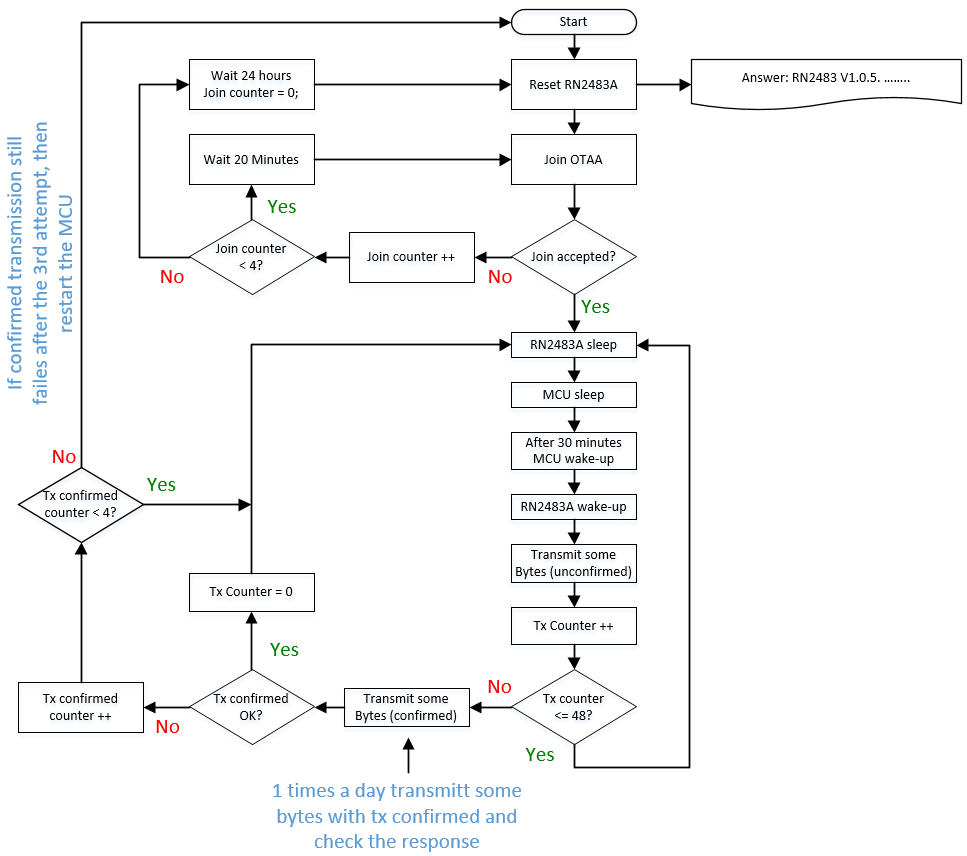
this is now my concept to make a robust communication on nodes side. After the join OTAA process and if join accepted, i send some bytes every 30 minutes with unconfirmed message. One times a day, i will send some bytes with confirmed message. If respond is ok, then repeat with unconfirmed message. If respond is not ok (after the 3rd try), restart the MCU.
LoRaWAN confirmed uplinks probably don’t actually do what you want.
First, if you are using ADR (which is almost a given with OTAA) then the ADR state machine itself gives you some idea of confirmed connectivity.
Next, the confirmed message scheme is badly thought out - if you’re going to use it, then at least modify the node to never retransmit on failure, instead make the next ordinary message confirmed as well. That’s because if it’s the downlink side of the confirmation that fails, then no matter how many times you re-transmit the uplink, you will never get a confirmation for that re-used frame count.
But ultimately, what do you hope to accomplish in the case of failure - how is resetting the MCU going to fix anything?
What I want to achieve is a stable connection. At least and this is important if a node cannot connect to the gateway for whatever reason. Maybe a problem with the software or the RN2483A module. Then the system should be able to reset itself and restart.
But human errors aside, what problems would be fixed by getting new secrets?
Your flow-chart is not trying to fix the reception quality (like by decreasing the data rate, like ADR would do). Also, it’s trying to get new secrets at a time when it knows something is wrong. Why would the OTAA Join succeed when the confirmed uplink failed? (Again, human errors aside.)